AI가 모르는 엔지니어링 지식, 지식 그래프로 해결
수십 년간 시니어 엔지니어 경험에 의존하던 설계 암묵지(Tacit Engineering Knowledge)의 유실 방지 및 AI 활용 방안 모색
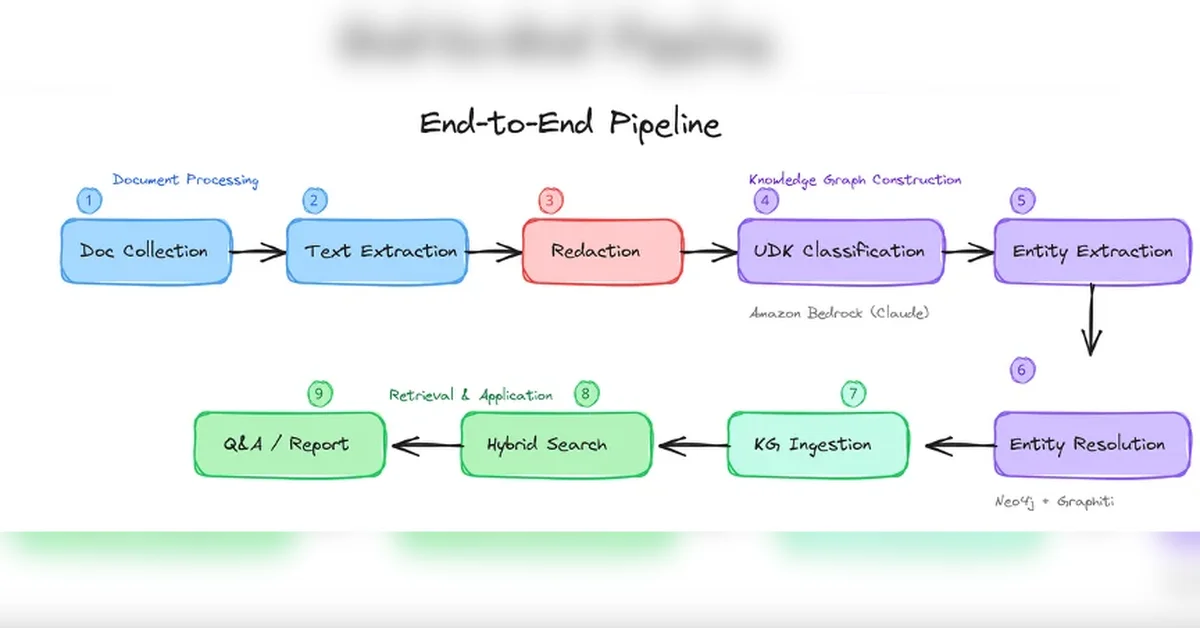
UDK(Untrained Domain Knowledge) 식별 및 3축 분류 체계(AI 학습 여부, 지식 성격, 범위)를 통해 80%의 미학습 지식 분류
Amazon Bedrock과 Graphiti 기반 시간적 지식 그래프(Temporal Knowledge Graph)를 활용하여 UDK 구조화 및 검색 가능성 검증
하이브리드 검색(Hybrid Search) 및 RRF 융합으로 정확도 높은 Q&A 및 영향도 분석 기능 구현
PoC 결과, 60초 내 문서 처리 및 Q&A 자동화 달성 및 설계 품질 편차 감소 기대
UDK(Untrained Domain Knowledge)의 정의와 분류
본문에서는 AI가 사전 학습하지 못한 도메인 지식을 UDK(Untrained Domain Knowledge)로 정의하며, 포스코DX의 PLC 제어 설계 규칙 중 80%가 여기에 해당함을 밝혔다. UDK는 AI 학습 여부, 지식의 성격(형식지/암묵지), 지식의 범위(자사/그룹/산업)라는 세 축으로 분류된다. 특히 문서화되지 않은 조직 고유의 암묵지(Tacit Knowledge)가 60%를 차지하며, 이는 시니어 엔지니어 퇴직 시 유실될 수 있는 핵심 경쟁력이다. 따라서 UDK를 체계적으로 식별하고 자산화하는 것이 AI 기반 설계 자동화의 핵심 과제임을 강조한다.
지식 그래프 기반 RAG의 필요성
기존 문서 기반 RAG(Retrieval-Augmented Generation)는 맥락 기반 검색, 변경 영향도 분석, AI 컨텍스트 주입에 한계가 있다. 설계 규칙 간의 복잡한 의존성(depends_on), 충돌(conflicts_with), 전제 조건(has_precondition) 관계를 표현하고 활용하기 위해서는 관계를 일급 시민(First-Class Citizen)으로 다루는 지식 그래프가 필수적이다. 본 PoC에서는 Graphiti 프레임워크를 사용하여 시간적 지식 그래프(Temporal Knowledge Graph)를 구축함으로써, 규칙의 유효 기간 관리와 출처 추적 기능을 강화했다.
하이브리드 검색과 RRF 융합 전략
다양한 형태의 엔지니어 질문에 대응하기 위해 벡터 검색(의미 유사도), BM25 키워드 검색, 그래프 순회(관계 추적)를 병렬로 수행하는 하이브리드 검색 방식을 채택했다. 각 검색 결과의 순위를 기반으로 융합하는 RRF(Reciprocal Rank Fusion) 기법을 통해, 서로 다른 스케일의 점수를 정규화할 필요 없이 최적의 검색 결과를 도출한다. 이를 통해 개념적 질문, 정확한 용어 검색, 관계 기반 추론 등 복합적인 요구사항을 만족시킨다.
시간적 지식 그래프의 핵심 기능: Entity Resolution & Temporal Fact Management
Graphiti는 Entity Resolution을 통해 'RULE-001', '예비 접점 확보 규칙' 등 동일 개념의 다양한 표현을 LLM 기반 의미 비교로 자동 병합하여 단일 노드로 관리한다. 또한, Temporal Fact Management는 모든 관계에 유효 기간(valid_from, valid_to)을 부여하여 규칙의 변경 이력을 추적하고 과거 설계 근거를 감사할 수 있게 한다. 이는 고정되지 않는 엔지니어링 지식의 특성을 반영한 핵심 기능이다.
데이터 보안 및 민감 정보 처리 방안
기업의 핵심 경쟁력인 설계 데이터 보호를 위해 아키텍처 수준의 격리를 원칙으로 한다. 원본 데이터는 고객 환경 내에서만 처리되며, 전송되는 것은 정제된 지식뿐이다. 2-Pass 민감 정보 제거 프로세스(LLM 기반 문맥 인식 Redaction 및 패턴 기반 이중 검증)를 통해 재현율을 높였으며, 저장 시 AES-256-GCM, 전송 시 TLS 1.3 암호화를 적용하여 다층 방어(Defense-in-Depth) 전략을 구현했다.
LLM 기반 지식 추출의 현실적 과제와 해결 방안
초기 LLM은 명사구 추출에 집중하여 임계값이나 배치 원칙 같은 핵심 판단 기준을 놓치는 경향이 있었다. 이를 해결하기 위해 시스템 프롬프트에 도메인 컨텍스트, 용어 사전, few-shot 예시를 주입하여 추출 품질을 개선했다. 또한, Entity Resolution의 정확도를 높이기 위해 엔티티 유형별 threshold 조정 및 negative example을 추가했으며, 관계 타입은 LLM이 자동으로 식별하도록 하여 IS_ABBREVIATION_FOR, HAS_PRECONDITION 등 유용한 관계를 발견했다.