온디바이스 AI, 얼굴 식별 파이프라인 최적화로 성능 530% 향상!
by DD
5개월 전
조회수 24
하이퍼커넥트(Hyperconnect)는 온디바이스(On-device) AI 사진 추천 기술의 핵심인 얼굴 식별 파이프라인(Face Verification Pipeline) 최적화 과정을 공개
얼굴 탐지(Face Detection) 모델의 디코딩(Decoding) 과정에서 불필요한 연산을 제거하고, top-K 선택 알고리즘을 힙 기반으로 변경하여 성능 개선
TensorFlow Lite 스레드 풀(Thread Pool) 크기를 디바이스 환경에 맞춰 조절하고, 모델 인스턴스 병렬화(Model Instance Parallelization)를 통해 처리량 극대화
모델 구조 변경 없이, 연산 흐름 개선 및 병렬 처리 기법을 통해 응답 시간 37% 단축, 처리량 530% 향상이라는 괄목할 만한 성과 달성
성능 최적화는 정량적 분석을 기반으로, 병목 지점(Bottleneck) 파악 및 디바이스 환경에 맞는 튜닝(Tuning)이 중요함을 강조
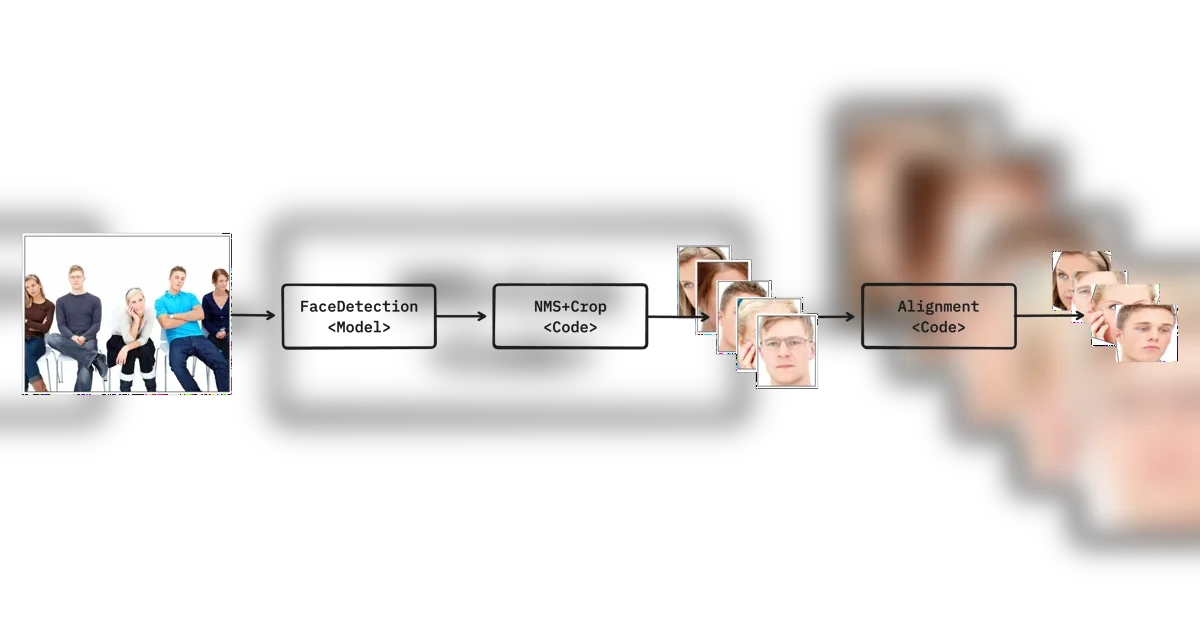
얼굴 식별 파이프라인(Face Verification Pipeline) 구조 분석
본문은 AI 사진 추천을 위한 얼굴 식별 파이프라인(Face Verification Pipeline)을 얼굴 탐지(Face Detection)와 얼굴 인식(Face Recognition) 두 단계로 구분하여 설명한다.
얼굴 탐지(Face Detection): 얼굴 탐지 모델(Face Detection Model)을 활용, 사진에서 얼굴 영역(Bounding Box)과 특징점(Landmark)을 추출
얼굴 인식(Face Recognition): 써드파티 라이브러리를 사용하여 임베딩(Embedding) 벡터 생성 및 유사도 계산