넷플릭스, AI 기반 멀티모달 영상 검색으로 창작 혁신을 이끌다!
by DD
3개월 전
조회수 48
방대한 영상 데이터(Video Data)에서 원하는 장면을 빠르게 찾기 위한 AI 기반의 멀티모달 검색 시스템(Multimodal Search System) 구축
다수의 특화 모델(Specialized Models)을 통합하여 영상의 장면, 객체, 대사 등을 분석하고, 데이터 격리 아키텍처(Data Isolation Architecture)를 통해 효율적인 검색을 지원
Apache Cassandra, Apache Kafka, Elasticsearch 등 다양한 기술을 활용하여 대규모 데이터 처리 및 실시간 검색 성능을 확보
자연어 처리(Natural Language Processing), 퍼지 매칭(Fuzzy Matching) 등 다양한 기술을 통해 검색 정확도(Search Accuracy)를 향상시키고, 사용자 맞춤형 검색 환경 제공
향후 자연어 기반 검색(Natural Language Discovery), 적응형 랭킹(Adaptive Ranking), 사용자 맞춤형 검색(Domain-Specific Personalization) 기능을 통해 검색 성능을 지속적으로 개선할 예정
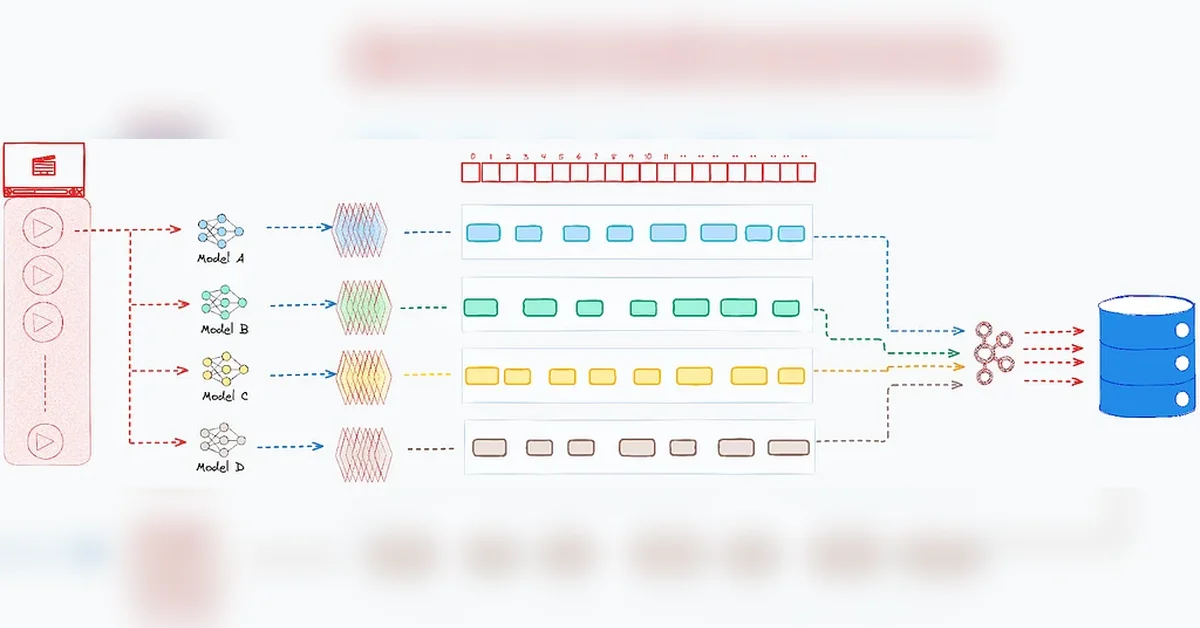
멀티모달 검색(Multimodal Search) 아키텍처
넷플릭스(Netflix)의 멀티모달 검색 시스템은 영상, 음성, 텍스트 등 다양한 모달리티(Modality)를 통합하여 검색 정확도를 높인다. 시스템은 크게 세 단계로 구성된다.
데이터 수집(Ingestion): 고가용성 파이프라인(High-Availability Pipelines)을 통해 원시 데이터를 수집하고, 에 저장하여 데이터 무결성(Data Integrity)을 보장한다.