넷플릭스, ML 모델 서빙 인프라 개선: Switchboard Lightbulb
by DD
2개월 전
조회수 48
넷플릭스는 ML 모델 서빙 플랫폼(ML Model Serving Platform)을 통해 다양한 개인화 경험을 제공하며, 100만 RPS(Requests Per Second)를 처리함
기존 Switchboard 아키텍처는 단일 진입점(Single Entry Point) 역할을 수행했지만, 지연 시간 증가(Latency Increase) 및 단일 실패 지점(Single Point of Failure) 문제를 야기함
Lightbulb 아키텍처는 Envoy 프록시(Envoy Proxy)를 활용하여 라우팅(Routing)을 분리하고, 지연 시간 감소(Latency Reduction) 및 확장성(Scalability) 향상을 달성함
Switchboard 아키텍처의 문제점
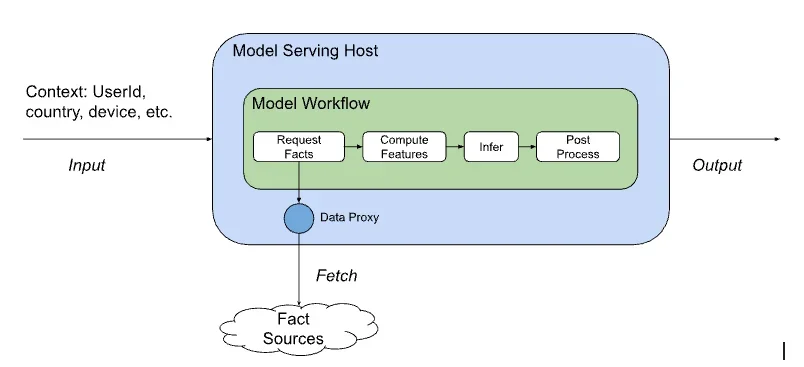
Switchboard는 넷플릭스 ML 모델 서빙 플랫폼의 핵심 컴포넌트였으나, 단일 실패 지점(Single Point of Failure)으로 작용하여 시스템 전체의 가용성을 저해했다. 특히, Switchboard 장애는 여러 ML 기반 서비스의 중단을 초래할 수 있었다. 또한, Switchboard는 모든 요청 경로에 포함되어 추가적인 지연 시간(Latency)을 유발했으며, 이는 사용자 경험에 부정적인 영향을 미쳤다. Switchboard는 클라이언트 요청의 기원을 가려, 테넌트 격리(Tenant Isolation) 및 트래픽 분석을 어렵게 만들었다. 이러한 문제점들은 시스템의 확장과 발전을 저해하는 주요 요인으로 작용했다.
Lightbulb 아키텍처의 핵심 원리
Lightbulb 아키텍처는 Switchboard의 문제점을 해결하기 위해 라우팅(Routing)과 모델 선택(Model Selection)을 분리했다. Lightbulb은 요청 메타데이터(Metadata)를 처리하고, Envoy 프록시(Proxy)는 실제 라우팅을 담당한다. Lightbulb은 요청 컨텍스트를 분석하여 라우팅 키(Routing Key)를 생성하고, Envoy는 이 키를 기반으로 요청을 적절한 클러스터로 전달한다. 이 방식은 Switchboard의 단일 실패 지점 문제를 해결하고, 지연 시간을 줄이는 데 기여했다. 또한, Lightbulb은 A/B 테스트(A/B Testing) 및 모델 버전 관리(Model Versioning)를 지원하여 유연성을 확보했다.
Envoy 프록시(Proxy)를 활용한 라우팅
Lightbulb 아키텍처에서 Envoy 프록시(Proxy)는 핵심적인 역할을 수행한다. Envoy는 L7 라우팅(L7 Routing) 기능을 통해 요청을 적절한 클러스터로 전달하며, 고가용성(High Availability)을 보장한다. Lightbulb은 Envoy에 필요한 라우팅 정보를 제공하며, Envoy는 이 정보를 기반으로 요청을 처리한다. Envoy는 HTTP/2(HTTP/2) 및 gRPC(gRPC)를 지원하여 다양한 프로토콜의 요청을 처리할 수 있다. Envoy의 사용은 시스템의 확장성을 높이고, 지연 시간(Latency)을 감소시키는 데 기여했다.
Switchboard Rules의 역할
Switchboard Rules는 모델 연구자들이 A/B 테스트(A/B Testing), 트래픽 분할(Traffic Splitting) 등을 설정할 수 있도록 지원하는 JavaScript 기반의 설정 파일이다. 이 규칙은 Switchboard와 모델 서빙 클러스터 모두에서 사용되며, 모델의 배포 및 관리를 용이하게 한다. Switchboard Rules는 Gutenberg 시스템을 통해 관리되며, 버전 관리, 동적 로딩, 롤백(Rollback) 기능을 제공한다. 이 시스템은 모델 배포(Model Deployment)의 유연성을 높이고, 연구자들이 모델을 안전하게 배포할 수 있도록 지원한다.
Lightbulb 아키텍처의 장점
Lightbulb 아키텍처는 Switchboard의 주요 장점인 단일 통합 지점(Single Integration Point), 모델 ID와 사용 사례의 추상화, 컨텍스트 기반 라우팅(Context-Aware Routing)을 유지하면서, 기존 아키텍처의 문제점을 해결했다. Lightbulb은 지연 시간(Latency) 감소, 확장성(Scalability) 향상, 가용성(Availability) 개선을 통해 넷플릭스 ML 모델 서빙 플랫폼의 성능을 향상시켰다. 또한, Lightbulb은 실험(Experimentation) 설정의 유연성을 높여, 연구자들이 새로운 모델을 안전하게 배포하고 실험할 수 있도록 지원한다.