Netflix, 미디어 데이터 엔지니어링으로 ML 성능 UP!
by DD
8개월 전
조회수 11
Netflix는 Media Data Engineering이라는 새로운 데이터 엔지니어링 전문 분야를 도입하여 미디어 데이터 처리 역량을 강화함
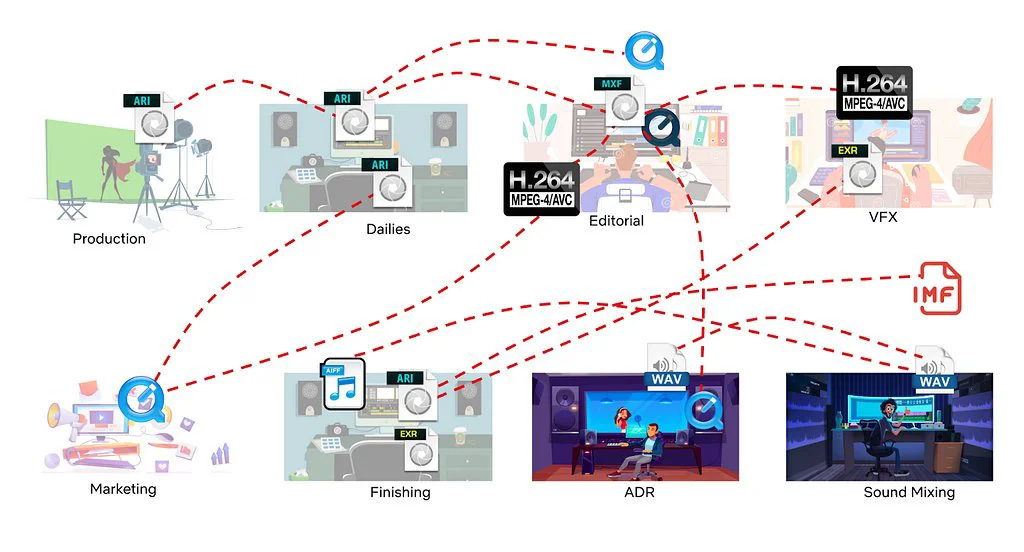
Media Data Lake를 구축하여 미디어 자산에 대한 중앙 집중식 접근 및 ML 활용을 지원함
LanceDB를 활용한 벡터 저장 솔루션 도입으로 ML 모델의 성능 향상 및 혁신적인 서비스 개발을 기대
Media Data Lake 아키텍처 심층 분석
Media Data Lake는 미디어 자산의 효율적인 관리와 ML 모델의 활용을 위해 설계되었다. 구체적으로, Media Table을 중심으로 데이터 모델과 Data API를 제공하여 데이터 접근성을 높인다. 따라서 온라인/오프라인 시스템 아키텍처를 통해 실시간 쿼리 및 대규모 배치 처리를 지원하며, GPU와 CPU를 활용한 컴퓨팅 자원을 제공한다.
전통적 데이터 엔지니어링 vs Media Data Engineering
전통적인 데이터 엔지니어링은 정형 데이터 처리에 초점을 맞춘 반면, Media Data Engineering은 비정형 미디어 데이터를 다룬다. 멀티 모달 데이터 처리, ML 모델 출력 통합, 대규모 데이터 처리를 위한 설계가 핵심이다. 따라서 데이터 표준화 및 메타데이터 관리를 통해 데이터 품질을 향상시키고, ML 모델의 성능을 극대화한다.
Media Data Engineering의 실질적 가이드
Media Data Engineering은 데이터 엔지니어, ML 연구원, 도메인 전문가 간의 협업을 강조한다. 데이터 품질 확보를 위해 데이터 표준화 및 메타데이터 관리에 집중해야 한다. 따라서 LanceDB와 같은 벡터 저장 솔루션을 활용하여 ML 모델의 성능을 향상시키고, 새로운 기능을 빠르게 개발할 수 있도록 지원해야 한다.