인덱싱 버그, 이제는 이름으로 해결하세요!
인덱싱(Indexing) 관련 버그는 개발 과정에서 흔히 발생하는 문제로, 코드의 가독성을 저해함
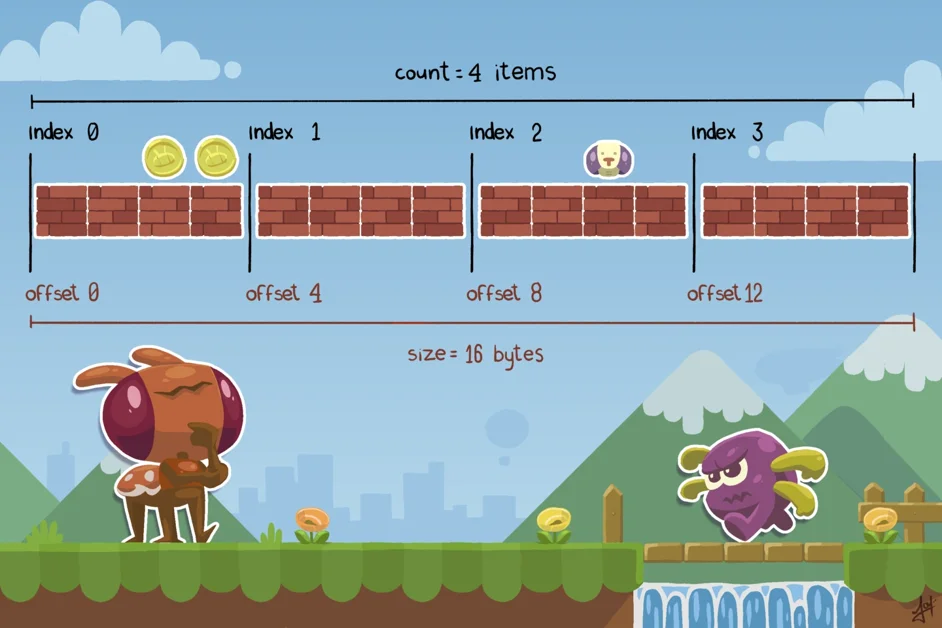
`count`, `index`, `size`, `offset`과 같은 명확한 네이밍 컨벤션(Naming Convention)을 통해 버그 발생 가능성을 줄일 수 있음
Rust와 Zig에서의 `len` 사용의 모호성을 지적하며, `size` 사용 시 발생할 수 있는 문제점도 언급됨
커뮤니티에서는 `count`와 `offset`을 활용한 페이징(Pagination) 구현 사례를 공유하며, 네이밍 컨벤션의 중요성을 강조함
인덱싱(Indexing) 관련 버그의 근본 원인
게시물에서는 인덱싱과 관련된 오프-바이-원 에러(Off-by-one Error)가 발생하는 근본적인 원인으로 모호한 변수명과 불일치하는 데이터 타입을 지적한다. 특히, `len`과 같이 의미가 불분명한 변수명은 코드의 가독성을 떨어뜨리고, 개발자가 의도치 않은 실수를 유발할 수 있다. Rust의 `str::len`과 Python의 `len(str)`의 차이점을 예시로 들며, 언어별로 다른 `len`의 의미를 명확히 인지해야 함을 강조한다.
네이밍 컨벤션(Naming Convention)의 구체적인 제안
게시물은 `count`, `index`, `size`, `offset`과 같은 명확한 변수명을 사용하여 인덱싱 관련 버그를 줄이는 방법을 제시한다. count는 항목의 총 개수를, index는 특정 항목을 가리키는 데 사용하며, size는 바이트 단위의 크기를, offset은 인덱스의 바이트 단위 대응 값을 의미한다. 이러한 컨벤션을 통해 코드의 일관성을 유지하고, 개발자가 변수의 의미를 쉽게 파악할 수 있도록 돕는다.
Rust와 Zig에서의 네이밍 컨벤션(Naming Convention) 적용 사례
게시물은 Rust와 Zig에서의 네이밍 컨벤션 적용 사례를 제시하며, 코드의 가독성과 유지보수성을 높이는 방법을 설명한다. 특히, TigerBeetle 프로젝트의 코드를 예시로 들며, `node_index`와 같은 변수명을 통해 인덱스 계산의 정확성을 확보하는 방법을 보여준다. 또한, 빅 엔디안 네이밍(Big Endian Naming)과 듀얼 네임(Dual Name)의 동일한 길이 유지를 통해 코드의 시각적 일관성을 높이는 방법을 제시한다.
네이밍 컨벤션(Naming Convention)의 한계와 보완점
댓글에서는 `size` 변수가 정수 타입의 상한값을 초과하는 경우에 대한 문제점을 지적하며, 포괄적인 범위(Inclusive Ranges)를 사용하는 대안을 제시한다. 또한, `len`과 같은 변수의 모호성을 피하기 위해 `bytesize` 또는 `bitlength`와 같은 명확한 변수명을 사용하는 방법을 제안한다. 이러한 보완점을 통해 네이밍 컨벤션의 효과를 극대화하고, 코드의 안정성을 높일 수 있다.