MoE, AI 모델 효율성의 새로운 지평을 열다!
by DD
11개월 전
조회수 14
MoE 아키텍처는 여러 전문가 네트워크를 활용하여 계산 효율성을 높임
GPT-4, DeepSeek 등 최신 LLM 모델에서 MoE를 채택하여 성능을 향상시킴
모델 병렬화, 양자화 등의 기술을 통해 MoE 모델 배포의 어려움을 해결
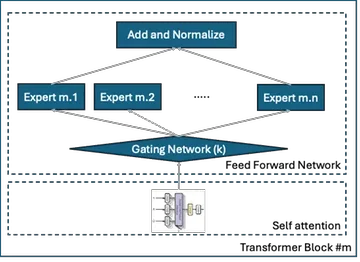
MoE 아키텍처의 핵심 원리
MoE(Mixture of Experts)는 게이팅 네트워크를 통해 입력에 따라 적합한 전문가를 선택한다. 구체적으로, 게이팅 네트워크는 입력 임베딩을 받아 각 전문가에 대한 로짓을 계산하고, Softmax를 통해 가중치를 생성한다. 따라서, 희소 활성화를 통해 연산량 감소와 파라미터 효율성 증가를 달성한다.
MoE의 장단점 심층 분석
MoE는 연산량 감소와 파라미터 효율성을 제공하지만, 모델 학습의 어려움과 추론 일관성 문제가 존재한다. 로드 밸런싱 문제와 통신 오버헤드는 MoE 배포의 주요 과제이다. 반면, 모델 병렬화와 양자화를 통해 GPU 메모리 사용량을 줄일 수 있다.
MoE 기반 서비스 배포 전략
MoE 모델 배포를 위해 모델 병렬화, 양자화, CPU Offloading 등의 기술을 활용한다. 전문가 병렬화는 MoE에 특화된 방식으로, All-to-All 통신을 최적화해야 한다. 따라서, 분산 서빙 프레임워크를 활용하여 처리량(throughput)을 극대화하고, Speculative Decoding으로 지연 시간(latency)을 단축한다.