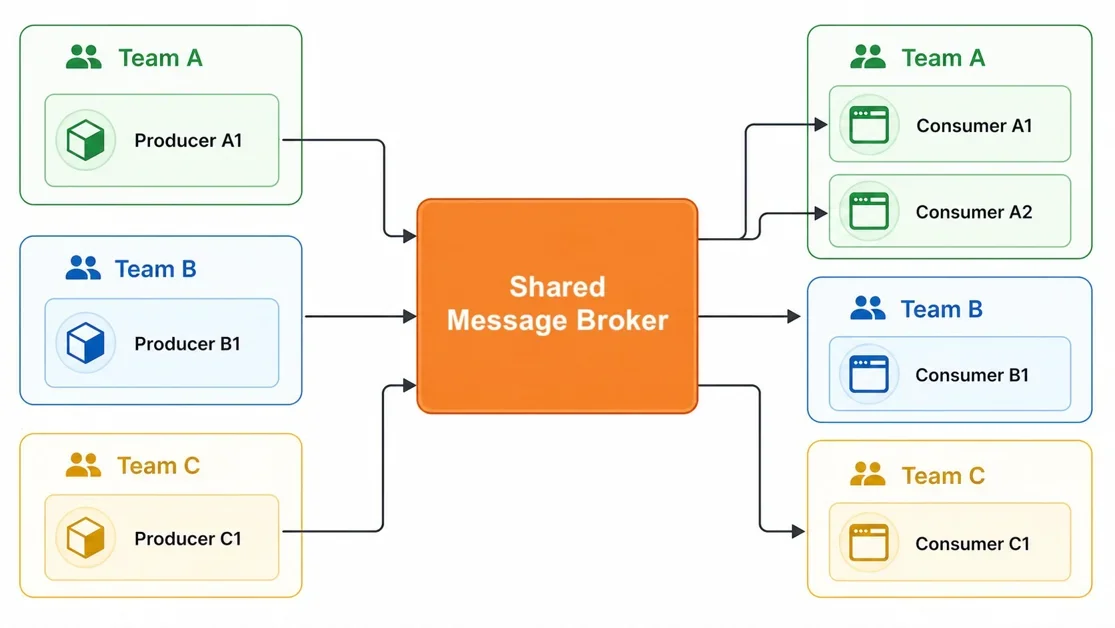
공유 메시지 브로커, 성능 저하와 운영 문제의 근본 원인?
by DD
2개월 전
조회수 14
메시지 브로커(Message Broker)가 공유 인프라로 확장되면서 성능 저하(Performance Degradation), 운영 복잡성 증가(Operational Complexity) 등의 문제 발생
Kafka의 파티셔닝(Partitioning) 설정, 리플레이(Replay) 기능 사용 시 다른 워크로드에 영향 미치는 사례 제시
공유 브로커 환경에서 데이터 격리(Data Isolation), 엄격한 접근 제한(Strict Access Control), 자동화된 가드레일(Automated Guardrails) 구축 필요
운영팀(Operating Team)과 개발팀(Development Team) 간의 책임 분담, 자가 치유(Self-Healing) 기능의 중요성 강조
공유 브로커 환경에서의 성능 저하 문제
공유 메시지 브로커(Message Broker) 환경에서 발생하는 가장 큰 문제 중 하나는 성능 저하(Performance Degradation)이다. 특히, 특정 팀의 과도한 부하(Heavy Load)가 다른 팀의 서비스에 영향을 미치는 경우가 빈번하게 발생한다. 예를 들어, 오래된 데이터를 리플레이(Replay)하는 과정에서 디스크 I/O(Disk I/O)가 증가하여 다른 워크로드의 지연 시간(Latency)이 증가하는 현상이 발생할 수 있다. 이러한 문제는 데이터 격리 아키텍처(Data Isolation Architecture) 부재로 인해 발생하며, 각 팀의 워크로드를 분리하여 관리하는 것이 중요하다.
파티셔닝(Partitioning) 설정의 중요성
Kafka의 파티셔닝(Partitioning) 설정은 시스템 성능에 매우 중요한 영향을 미친다. 파티션 키(Partition Key) 선택은 데이터의 정렬 순서, 로드 분산, 병렬 처리 수준을 결정하는 핵심 요소이다. 저 카디널리티(Low-Cardinality) 키를 선택하면 핫 파티션(Hot Partition)이 발생하여 특정 브로커에 부하가 집중될 수 있다. 반면, 무작위 키를 사용하면 정렬 순서가 깨질 수 있다. 따라서, 파티셔닝 모델(Partitioning Model) 설계 시 데이터 특성을 고려하여 트레이드오프(Trade-offs)를 신중하게 결정해야 한다.
리플레이(Replay) 기능 사용 시 주의사항
리플레이(Replay) 기능은 데이터 복구 및 분석에 유용하지만, 신중하게 사용해야 한다. 리플레이는 과거 데이터를 현재 코드에 적용하는 과정이므로, 데이터베이스, 캐시, 외부 API 등 다른 시스템에 부하를 가중시킬 수 있다. 특히, 외부 시스템 호출이 많은 경우, 리플레이로 인해 해당 시스템의 성능 저하가 발생할 수 있다. 따라서, 리플레이 시에는 외부 시스템에 미치는 영향(Impact on External Systems)을 고려하고, 충분한 용량(Capacity)을 확보해야 한다.
공유 브로커 운영을 위한 가드레일(Guardrails) 구축
공유 브로커 환경에서는 엄격한 접근 제한(Strict Access Control)과 자동화된 가드레일(Automated Guardrails) 구축이 필수적이다. 개발팀은 브로커의 용량, 파티션 수, 데이터 보존 기간 등을 고려하지 않고 설정을 변경할 수 있다. 이러한 무분별한 설정은 시스템 전체의 안정성을 저해할 수 있으므로, 자동화된 스키마 검증(Automated Schema Validation), 리플레이 승인 절차(Replay Approval Process) 등을 통해 안전한 운영 환경을 구축해야 한다. 또한, 데이터 미저장 정책(Zero-Retention Policy)을 통해 불필요한 데이터 보관을 방지해야 한다.
운영팀(Operating Team)과 개발팀(Development Team)의 역할 분담
공유 브로커의 성공적인 운영을 위해서는 운영팀(Operating Team)과 개발팀(Development Team) 간의 명확한 역할 분담이 필요하다. 개발팀은 메시지 토픽, 키, 페이로드 크기, 재시도(Retry) 정책 등을 결정하고, 운영팀은 시스템의 안정성과 성능을 책임진다. 운영팀은 모니터링(Monitoring) 및 알림 시스템(Alerting System)을 통해 문제 발생 시 신속하게 대응하고, 개발팀은 자가 치유(Self-Healing) 기능을 구현하여 시스템의 복원력을 높여야 한다. 이러한 협력을 통해 효율적인 운영 환경을 구축할 수 있다.