LLaDA: 디퓨전 모델로 LLM의 한계를 돌파하다!
by DD
6개월 전
조회수 8
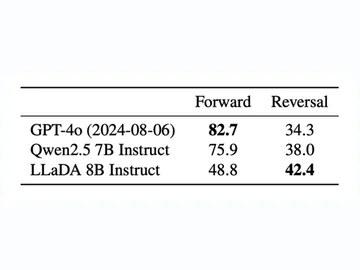
LLaDA는 디퓨전 모델을 활용하여 LLM reversal curse 문제를 해결함
Auto-regressive LM과 달리 양방향 어텐션을 통해 시퀀스 학습 가능
추론 속도는 빠르지만, KV-cache 미지원으로 효율성 개선 필요
LLaDA의 핵심 원리: 디퓨전과 마스킹
LLaDA는 텍스트 시퀀스에 노이즈를 추가하는 디퓨전 개념을 활용한다. 구체적으로, 텍스트 토큰을 마스킹하여 노이즈를 주입하고, 마스킹된 토큰으로부터 원래 텍스트를 예측하는 방식으로 학습한다. 따라서, 전체 시퀀스에 대한 어텐션을 얻어 LLM reversal curse를 해결한다.
LLaDA의 장단점: 속도 vs 효율성
LLaDA는 전체 토큰을 한 번에 생성하여 빠른 추론 속도를 제공한다. 반면, KV-cache를 지원하지 않아, 시퀀스 길이가 길어질수록 계산 복잡도가 증가한다. 따라서, LLaDA는 추론 속도를 높이는 대신, 메모리 사용량과 계산 비용 측면에서 불리하다.
LLaDA의 실전 적용: 코드 생성 가능성
LLaDA는 코드 생성 분야에서 FIM(Fill-in-the-middle) 문제를 해결할 가능성을 제시한다. 구체적으로, 코드의 앞뒤 부분을 주고 가운데를 채우는 문제에 강점을 보인다. 따라서, 코드 특화 모델로 활용하여 생산성 향상을 기대할 수 있으며, Gemini diffusion의 코드 생성에 대한 기대감을 높인다.