쿠버네티스 스케줄러, 코드 레벨에서 파헤치기!
쿠버네티스 스케줄러(Kubernetes Scheduler)의 동작 방식을 코드 레벨에서 분석하여, 파드(Pod) 스케줄링 과정을 심층적으로 이해
Affinity, Taint, NodeName 등 다양한 스케줄링 관련 설정을 통해 워크로드(Workload) 배포 전략을 세밀하게 설계하는 방법 제시
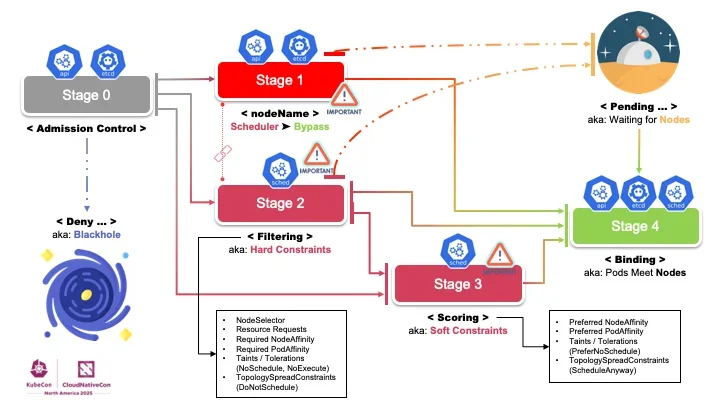
Stage1, 2, 3으로 구분하여 스케줄러의 핵심 동작 원리를 설명하고, 실제 yaml 파일과 깃허브(GitHub) 저장소를 활용한 실습 환경 제공
NodeName 설정 시 스케줄러를 거치지 않고 바로 노드에 배치되는 동작 방식과 Taint/Toleration의 상호 작용 분석
필터(Filter)와 스코어(Score)의 우선순위에 따른 파드 배포 변화를 실습하며, 쿠버네티스(Kubernetes) 환경에서의 유연한 워크로드 관리 강조
쿠버네티스 스케줄러(Scheduler)의 핵심 구조
본문은 쿠버네티스 스케줄러(Kubernetes Scheduler)의 동작 과정을 Stage1, 2, 3으로 구분하여 설명한다. Stage1은 nodeName 설정을 처리하며, 스케줄러를 거치지 않고 바로 해당 노드로 파드를 배치한다. Stage2는 NodeSelector, Resource Requests, Required NodeAffinity 등 필터를 적용하여 실행 가능한 노드를 결정한다. Stage3에서는 Preferred NodeAffinity, Preferred PodAffinity 등 스코어(Score)를 계산하여 최종적으로 파드를 배치할 노드를 선택한다. 이러한 구조는 쿠버네티스(Kubernetes)가 제공하는 유연한 워크로드 관리의 핵심이다.
NodeName 설정과 Taint/Toleration의 상호 작용
글에서는 nodeName 설정을 통해 Taint가 설정된 노드에도 파드를 배치할 수 있음을 보여준다. nodeName이 지정되면 스케줄러의 필터링 과정을 우회하기 때문이다. 이는 특정 노드에 파드를 즉시 배치해야 하는 경우 유용하지만, Taint/Toleration 설정을 통해 노드 사용을 제한하는 의도와 상충될 수 있다. 따라서 nodeName 사용 시에는 Taint/Toleration 설정을 신중하게 고려해야 하며, 데이터 격리 아키텍처(Data Isolation Architecture)를 위한 노드 설계를 할 때 주의해야 한다.
필터(Filter)와 스코어(Score)의 우선순위
쿠버네티스 스케줄러(Kubernetes Scheduler)는 필터(Filter)와 스코어(Score)를 통해 파드(Pod)를 배치할 노드를 결정한다. 필터는 NodeSelector, Resource Requests, Required NodeAffinity 등을 사용하여 실행 가능한 노드를 걸러낸다. 스코어는 Preferred NodeAffinity, Preferred PodAffinity 등을 기반으로 각 노드에 점수를 매긴다. 필터는 스코어보다 먼저 적용되므로, 필터 조건을 만족하지 못하는 노드는 스코어 계산 대상에서 제외된다. 이러한 구조는 유연한 스케줄링(Flexible Scheduling)을 가능하게 하지만, 설정 오류 시 예상치 못한 결과가 발생할 수 있으므로 주의해야 한다.
실습 환경 구축 및 활용
본문은 쿠버네티스 스케줄러(Kubernetes Scheduler)의 동작을 이해하기 위해 실습 환경 구축 방법을 상세히 안내한다. 베이그런트(Vagrant), 버추얼박스(VirtualBox)를 사용하여 쿠버네티스 클러스터를 구성하고, 깃허브(GitHub) 저장소에서 제공하는 yaml 파일을 활용하여 실습을 진행한다. 특히, nodeName, 필터, 스코어(Score)에 따른 파드(Pod) 배포 결과를 직접 확인하며, 쿠버네티스(Kubernetes) 환경에서의 배포 전략을 학습할 수 있다. 이러한 실습은 쿠버네티스 스케줄러의 동작 원리를 깊이 있게 이해하는 데 도움을 준다.
코드 분석을 통한 쿠버네티스(Kubernetes) 이해
글에서는 쿠버네티스 스케줄러(Kubernetes Scheduler)의 동작 방식을 코드 레벨에서 분석하는 방법을 제시한다. 공식 문서를 넘어, 실제 코드를 직접 살펴보는 과정을 통해 쿠버네티스의 내부 동작 원리를 더 깊이 있게 이해할 수 있다. 특히, AI의 도움을 받아 코드 분석을 시작하고 연관된 부분을 찾아 해석하는 방법을 소개한다. 이러한 접근 방식은 쿠버네티스(Kubernetes)와 같은 대형 프로젝트의 코드를 이해하는 데 필요한 시간과 노력을 줄여주며, DevOps 엔지니어의 역량 강화에 기여한다.