멀티모달 AI, 한국어 이해부터 화면 조작까지!
by DD
4개월 전
조회수 8
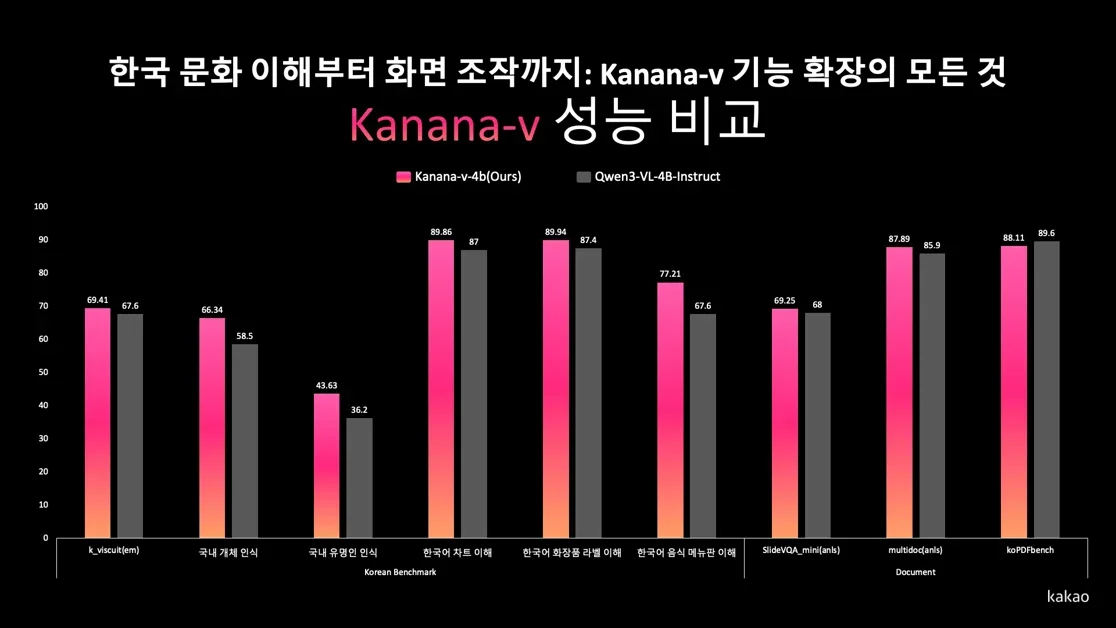
카카오 AI팀은 텍스트, 이미지, 음성을 이해하는 멀티모달 언어 모델을 개발하며, 한국어 데이터셋(Korean Dataset) 정제를 통해 모델의 한국어 이해 능력 강화
PDF 벤치마크(PDF Benchmark) 자체 구축 및 다중 이미지, Long-Context 학습 최적화를 통해 VLM(Vision Language Model)의 PDF 이해 능력 향상
다중 이미지 이해(Multi-Image Understanding)를 위해 데이터 증강(Data Augmentation) 기법을 도입하여 모델의 할루시네이션(Hallucination) 완화
CUA(Computer Use Agent)의 핵심 기술인 GUI Grounding을 소개하며, API가 없는 환경에서의 자동화 가능성을 제시
Interleaved 한국어 데이터셋 구축 및 효과
본문에서는 VLM(Vision Language Model)이 한국 문화를 더 깊이 이해하도록 Interleaved 한국어 데이터셋을 적용한 실험을 소개한다. 데이터 품질(Data Quality) 확보를 위해 Datatrove 프레임워크를 활용하여 8단계 정제 파이프라인을 구축했다.
이미지 기반 문서 필터링(Image-based Document Filtering): 깨진 이미지, 저해상도 이모티콘 등 제거
언어 식별(Language ID): FastText 기반 모델로 한국어 콘텐츠 선별 (90% 이상)
반복 패턴 제거(Gopher Repetition Filter): DeepMind의 Gopher 논문에서 제안된 휴리스틱 적용
기본 품질 필터(Gopher Quality Filter): 평균 단어 길이, 불용어 출현 빈도 등 검증