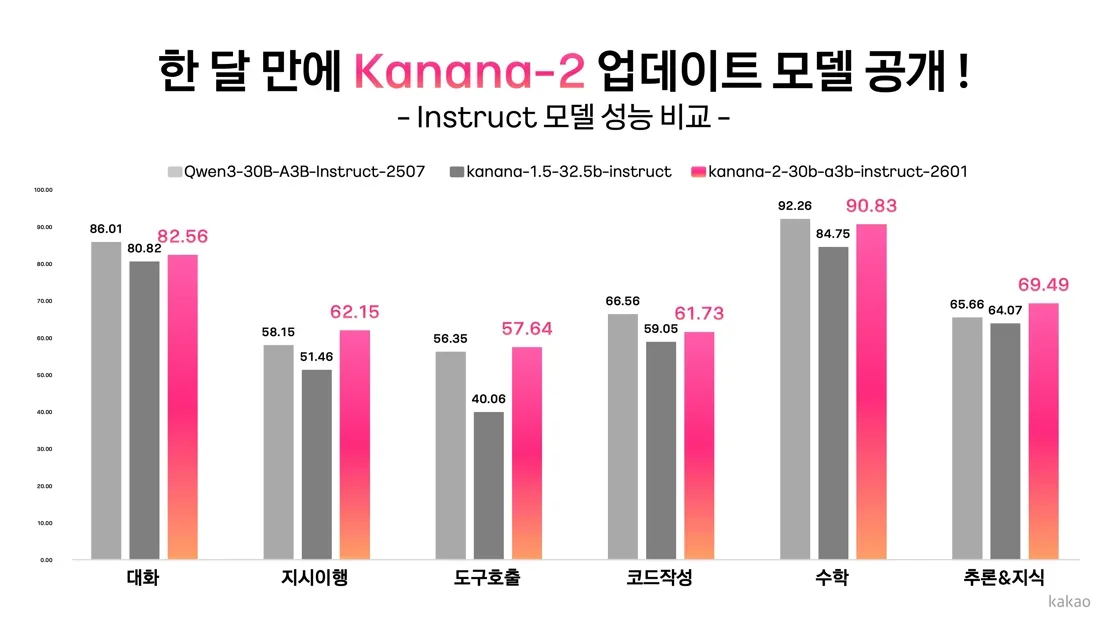
카카오, Kanana-2 모델로 Agentic AI 성능 대폭 향상
by DD
6개월 전
조회수 24
Mid-training을 통해 모델의 추론 능력과 특정 역할 수행 능력을 강화하고, 데이터 효율성(Data Efficiency)을 증대
SFT(Supervised Fine-Tuning) 단계에서 Chat, Math, Code, Tool Calling 등 도메인별로 최적의 데이터 구성 방식을 적용하여 Instruction Following 및 Tool Calling 능력 향상
Parallel RL(병렬 강화 학습) 파이프라인 도입으로 태스크 간 수렴 시점 불균형 문제를 해결하고, 훈련 효율성을 극대화
Calibration Tuning을 통해 병합 과정에서 발생한 성능 저하를 보완하고, 각 도메인별 최고 성능을 성공적으로 복원
Mid-training: 추론 능력 강화를 위한 핵심 전략
본문에 따르면 Mid-training은 Pre-training과 Post-training 사이의 중간 훈련 단계로, 모델이 특정 능력을 효과적으로 습득하도록 돕는다. 특히, 추론 및 논리적 사고 능력 강화를 위해 수학, 코드, 툴, 일반 대화 등 다양한 도메인의 데이터를 활용했다. 또한, Pre-training 데이터 리플레이(Pre-training Data Replaying) 전략을 통해 특정 언어/벤치마크에서의 성능 저하를 방지하고, 균형 잡힌 모델을 구축했다. 결과적으로 Mid-training은 '범용적인 언어 이해력'을 '특정 목표 지향적인 고성능 능력'으로 전환하는 가교 역할을 수행한다. 200B 토큰 규모의 고품질 영어 추론 데이터셋과 50B의 한국어 Pre-trained replay 데이터를 포함하는 250B의 Mid-training 데이터셋을 구성하여 Kanana-2 Mid-trained 모델을 훈련했다.
Instruct 모델: Instruction Following 및 Tool Calling 능력 극대화
Kanana-2 Instruct 모델은 Mid-training을 기반으로 SFT(Supervised Fine-Tuning)와 RL(Reinforcement Learning)을 통해 완성되었다. SFT 단계에서는 Chat, Math, Code, Tool Calling 등 각 도메인에 대해 최적의 데이터 구성 방식을 실험적으로 적용했다. 특히, Instruction Following RL 훈련을 위해 멀티턴(Multi-turn) 데이터를 직접 제작하고, Blueprint 에이전트(Blueprint Agent)를 활용하여 대화 설계도를 생성했다. 또한, Tool Calling 능력 향상을 위해 Exact Match 기반의 엄격한 보상 함수(Reward Function)를 설계하여, 불필요한 도구 호출을 방지하고, 멀티턴 환경에서의 정확도를 높였다.
Parallel RL 파이프라인: 훈련 효율성 및 성능 극대화
Kanana-2 개발에서는 기존 레시피의 한계였던 태스크 간 수렴 시점 불균형 문제를 해결하기 위해 Parallel RL(병렬 강화 학습) 파이프라인을 도입했다. Instruction Following, Tool Calling, Math, Coding 등 각 태스크를 독립적인 파이프라인으로 분리하여 강화 학습을 수행함으로써, 태스크별 최적의 훈련 스텝과 하이퍼파라미터를 적용할 수 있었다. 또한, 레시피 변경 실험의 반복 속도를 개선하여 전체 개발 효율을 높였다. Merging & Calibration 단계를 통해 태스크별로 최적화된 모델들을 하나의 강력한 Kanana-2 Instruct 모델로 통합했다. 이로 인해, 각 도메인에서 최고 성능을 보인 개별 모델들의 성능을 유지하면서, 통합 모델의 성능을 향상시킬 수 있었다.
Thinking 모델: 심층 추론 능력과 한국어 답변 능력 강화
Instruct 모델이 사용자의 지시 이행에 초점을 맞춘다면, Thinking 모델은 심층 추론 과정을 통해 복잡한 문제를 해결하는 데 특화되었다. Thinking SFT 단계에서는 고품질의 사고 과정을 가진 응답만을 엄선하여 학습 밀도를 높였다. 특히, 한국어 질문 → 영어 사고 과정 → 한국어 답변 구조를 채택하여, 영어의 방대한 지식을 활용하면서도 한국어 답변 능력을 유지했다. 또한, Instruct 섹션에서 제안한 Parallel RL 전략을 도입하여, 지시 이행과 도구 호출 성능을 극대화하면서도 기존의 문제 해결 성능을 안정적으로 유지했다. GRPO 알고리즘을 적용하고, DAPO에서 제안한 clip_higher를 도입하여 탐색의 다양성을 확보했다. Kanana-2 Thinking 모델은 Mid-training, SFT, Parallel RL, Merge 및 Calibration에 이르는 정교한 학습 과정을 거쳤다.
Calibration Tuning: 성능 복원을 위한 핵심 기술
Parallel RL을 통해 확보한 모델들을 하나의 Kanana-2 Instruct 모델로 통합하는 과정에서, 성능 저하를 보완하기 위해 Calibration Tuning을 도입했다. Merging 직후의 모델에 대해 짧은 추가 SFT를 수행하여, 병합 과정에서 흐트러진 능력 분포를 재정렬하는 것을 목표로 했다. 각 태스크별 최고 성능 모델을 사용하여 응답을 생성하고, RL 훈련에서 사용한 것과 동일한 프롬프트 포맷 및 데이터 구조를 적용했다. Calibration SFT는 모델의 전반적인 능력 분포를 크게 변화시키지 않으면서도, 각 도메인에서 기대하는 최고 수준의 성능을 빠르게 복원하도록 유도하는 역할을 했다. Calibration Tuning 이후, Merged 모델은 Instruction Following, Tool Calling 등 서비스 핵심 영역을 포함한 전 도메인에서 개별 모델이 달성했던 최고 성능을 성공적으로 복원할 수 있었다.