IResearch, 적응형 압축으로 검색 엔진 성능을 혁신하다!
by DD
2개월 전
조회수 6
IResearch는 적응형 압축(Adaptive Compression) 기술을 활용하여 인덱싱 엔진의 저장 공간 절약 및 쿼리 속도 향상을 달성함
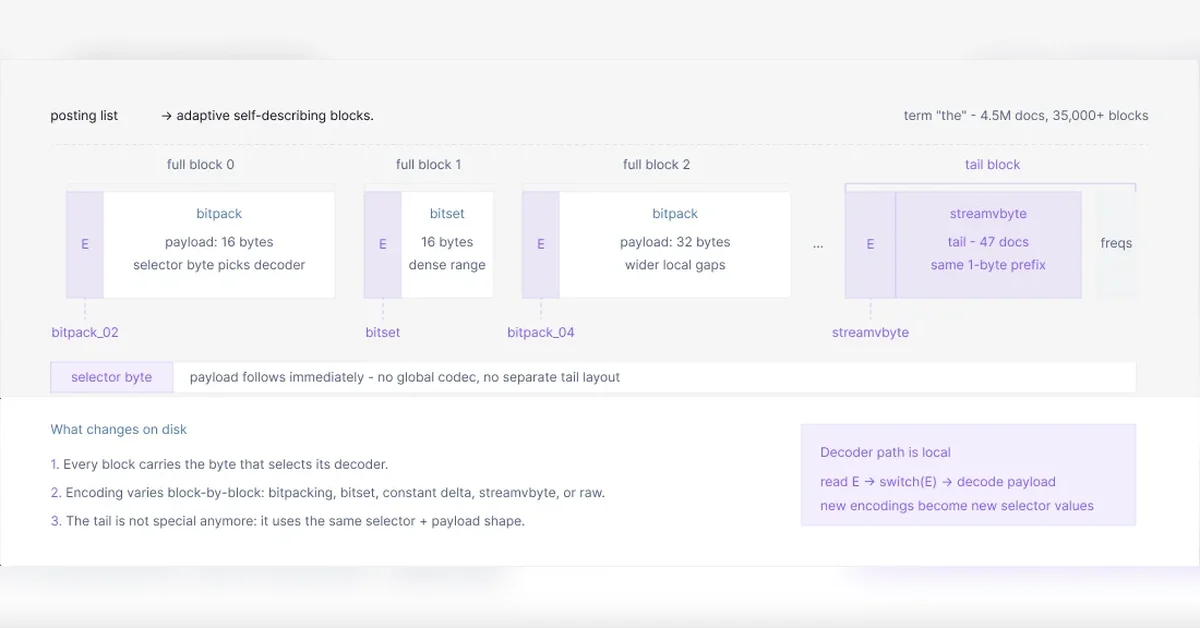
블록 단위(Per-Block)로 최적의 압축 방식을 선택하는 방식으로, 데이터 분포에 따라 FOR-delta, bitset, StreamVByte 등 다양한 인코딩 기법을 적용함
특히, 희소 용어(Rare Terms) 처리를 위해 VInt tail 방식을 제거하고, 모든 블록에 동일한 압축 경쟁을 적용하여 성능을 개선함
SIMD 기반의 비트셋(Bitset) 구현을 통해 디코딩 속도를 향상시키고, seek 연산의 효율성을 극대화함
적응형 압축 방식의 핵심 원리
IResearch는 블록 단위(Per-Block)로 최적의 압축 방식을 선택하는 적응형 압축 방식을 채택했다. 이는 데이터 블록 내 값의 분포가 다양하다는 점에 착안하여, 각 블록에 가장 적합한 인코딩을 동적으로 선택하는 방식이다. FOR-delta, bitset, StreamVByte 등 다양한 인코딩 기법을 활용하여 압축률을 극대화하고, 쿼리 성능을 향상시켰다. 특히, 희소 용어(Rare Terms)의 경우, StreamVByte를 활용하여 압축 효율을 높였다.
비트셋(Bitset) 인코딩의 SIMD 최적화
IResearch는 비트셋(Bitset) 인코딩의 디코딩 성능을 향상시키기 위해 SIMD(Single Instruction, Multiple Data) 기술을 활용했다. 구체적으로, 컴파일 타임(Compile Time)에 생성된 256개의 엔트리를 가진 룩업 테이블(Lookup Table)을 사용하여, AVX2 명령어를 통해 비트셋의 값을 빠르게 추출한다. 이를 통해, seek 연산의 효율성을 유지하면서도 디코딩 속도를 3배 향상시켰다. SIMD 최적화(SIMD Optimization)는 성능 향상의 핵심 요소이다.
VInt tail 제거를 통한 성능 개선
기존의 Lucene 및 Tantivy는 tail block에 VInt 인코딩을 사용하여, 블록 단위 압축의 이점을 활용하지 못했다. IResearch는 이러한 VInt tail 방식을 제거하고, 모든 블록에 동일한 압축 경쟁을 적용하여 성능을 개선했다. 이를 통해, 희소 용어(Rare Terms)의 경우에도 블록 단위 압축을 적용하여 저장 공간을 절약하고, 쿼리 성능을 향상시켰다. Tail 블록 처리(Tail Block Handling)의 효율성 개선은 중요한 성과이다.
향후 개선 방향 및 확장성
IResearch는 향후 AVX-512를 활용하여 SIMD 연산의 효율성을 더욱 높이고, 블록 크기를 256개로 확장하는 방안을 고려하고 있다. 또한, bitset 기반의 seek 연산을 직접 구현하여, 불필요한 데이터 변환을 제거할 계획이다. 이러한 개선을 통해, IResearch는 검색 엔진의 성능을 지속적으로 향상시키고, 다양한 데이터 환경에 유연하게 대응할 수 있을 것으로 기대된다. 확장성(Extensibility)을 고려한 설계는 IResearch의 강점이다.