Cloudflare, 에이전트의 기억력을 향상시키는 Agent Memory 출시!
by DD
3개월 전
조회수 4
에이전트(Agent)의 컨텍스트 창(Context Window) 크기 증가에도 불구하고 발생하는 컨텍스트 로테이션(Context Rot) 문제를 해결하기 위해 개발됨
Agent Memory는 에이전트 대화에서 정보를 추출하여 필요할 때 사용할 수 있도록 지원하며, 지속적인 메모리(Persistent Memory)를 제공함
Durable Object, Vectorize, Workers AI를 활용하여 메모리 저장, 검색, 합성을 수행하며, Cloudflare Workers 환경에서 작동함
에이전트(Agent)의 장기적인 지식(Long-term Knowledge)을 확보하여 팀 협업 및 지식 공유를 지원하며, 데이터 내보내기(Data Export) 기능을 제공함
Agent Memory의 핵심 아키텍처
Agent Memory는 Durable Object를 사용하여 각 메모리 프로필을 격리하고, SQLite 기반 저장소(SQLite-backed store)를 통해 데이터 격리(Data Isolation)를 보장한다. 또한, Vectorize를 활용하여 임베딩된 메모리에 대한 벡터 검색을 수행하며, Workers AI를 통해 LLM(Large Language Model) 및 임베딩 모델을 실행한다.
Durable Object: 메시지 및 분류된 메모리 저장
Vectorize: 임베딩된 메모리에 대한 벡터 검색 제공
Workers AI: LLM 및 임베딩 모델 실행
이러한 구성 요소들은 Cloudflare의 인프라 위에서 효율적으로 작동하며, 높은 확장성과 성능을 제공한다.
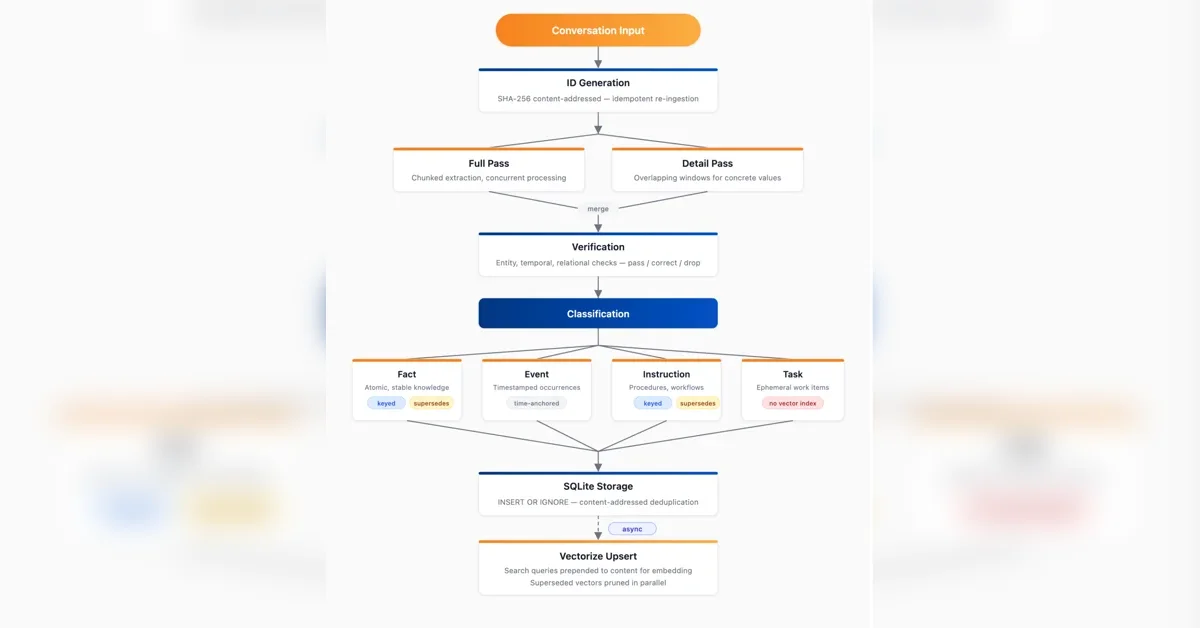
Agent Memory의 Ingestion 파이프라인
Agent Memory의 Ingestion 파이프라인은 여러 단계로 구성되어 메모리를 추출, 검증, 분류 및 저장한다. 먼저, 각 메시지는 SHA-256 해시(SHA-256 Hash)를 기반으로 하는 고유 ID를 생성하여 중복을 방지한다. 추출 단계에서는 메시지를 청크(Chunk)로 나누어 정보를 추출하고, 추출된 정보는 Entity Identity, Object Identity, Temporal Accuracy 등 8가지 검증을 거친다.
ID 생성: SHA-256 해시 기반 고유 ID 생성
추출: 메시지 청크 및 정보 추출
검증: 8가지 항목 검증
검증된 메모리는 Fact, Event, Instruction, Task의 4가지 유형으로 분류되며, 효율적인 데이터 관리를 위해 INSERT OR IGNORE를 사용한다.
Agent Memory의 Retrieval 파이프라인
Agent Memory의 Retrieval 파이프라인은 쿼리 분석 및 임베딩을 시작으로, 5개의 병렬 검색 채널을 통해 결과를 융합한다. 쿼리 분석 단계에서는 Topic Key, Full-text Search Term, HyDE(Hypothetical Document Embedding)를 생성하고, 이를 기반으로 임베딩을 수행한다. 5개의 검색 채널은 Full-text Search, Exact Fact-key Lookup, Raw Message Search, Direct Vector Search, HyDE Vector Search를 포함한다.
쿼리 분석: Topic Key, Full-text Search Term, HyDE 생성
검색 채널: 5개의 병렬 검색 채널 실행
결과 융합: Reciprocal Rank Fusion(RRF) 사용
최종적으로, RRF(Reciprocal Rank Fusion)를 통해 융합된 결과는 합성 모델(Synthesis Model)에 전달되어 자연어 답변을 생성한다.
Agent Memory의 성능 최적화
Agent Memory는 성능 향상을 위해 다양한 최적화 기법을 적용했다. 특히, Llama 4 Scout(17B, 16-expert MoE)를 사용하여 추출, 검증, 분류 및 쿼리 분석을 수행하고, Nemotron 3(120B MoE, 12B active parameters)를 사용하여 자연어 답변을 생성한다. 또한, Durable Object를 통해 메모리 프로필을 격리하고, Vectorize를 활용하여 효율적인 벡터 검색을 지원한다.
모델 선택: Scout(추출/분석), Nemotron(합성)
데이터 격리: Durable Object를 통한 메모리 프로필 격리
벡터 검색: Vectorize를 활용한 효율적인 검색
이러한 최적화는 Agent Memory의 전반적인 성능을 향상시키고, 에이전트의 효율적인 운영을 가능하게 한다.
Agent Memory의 활용 사례 및 확장성
Agent Memory는 다양한 에이전트 아키텍처에서 활용될 수 있으며, 팀 협업 및 지식 공유를 지원한다. 개별 에이전트의 메모리, 사용자 정의 에이전트 하네스, 여러 에이전트 간의 공유 메모리 등 다양한 시나리오에서 활용 가능하다. 특히, 코딩 에이전트(Coding Agent), 코드 리뷰어(Code Reviewer), 챗봇(Chatbot) 등에서 활용되어 팀의 지식 자산 구축에 기여한다.
개별 에이전트: Claude Code, OpenCode
팀 협업: 코딩 컨벤션, 아키텍처 결정 공유
확장성: 다양한 에이전트 아키텍처 지원
Agent Memory는 에이전트의 성능 향상뿐만 아니라, 팀의 지식 관리 및 공유를 위한 핵심적인 도구로 자리매김할 것으로 예상된다.