GraphRAG Toolkit으로 RAG 시스템의 지식 검색 능력을 극대화하세요!
by DD
2개월 전
조회수 42
기존 RAG 방식의 한계 극복을 위해 지식 그래프(Knowledge Graph)를 활용하여 데이터 간의 복잡한 관계를 파악하고, 정확한 정보 검색(Accurate Information Retrieval)을 가능하게 함
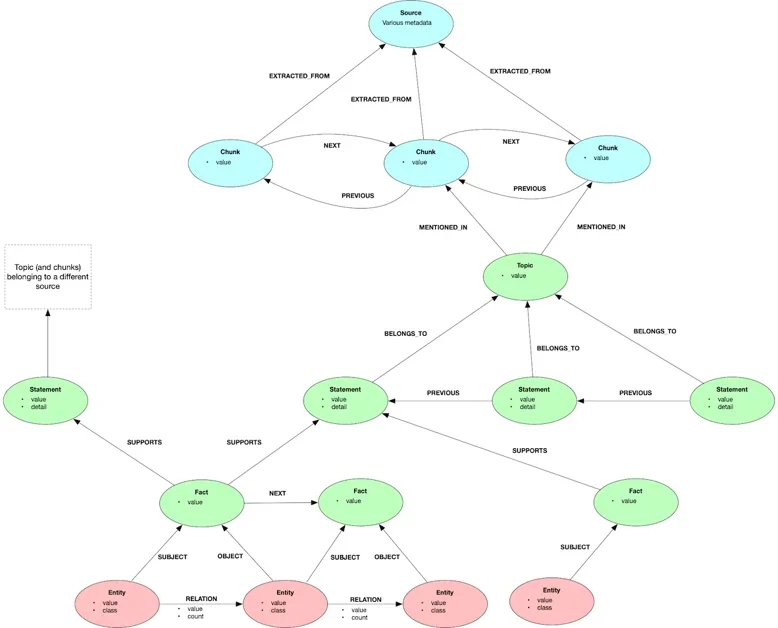
GraphRAG Toolkit을 사용하여 비정형 텍스트 문서에서 정보를 추출하고, 그래프 저장소(Graph Store)와 벡터 저장소(Vector Store)를 결합한 인덱스를 구축하는 방법을 제시
어휘 그래프(Lexical Graph) 모델을 기반으로, 문장(Statement) 단위의 계층적 구조를 통해 검색 효율성(Search Efficiency)을 향상시키고, 쿼리 실행 테스트를 수행
추출(Extract) 및 구축(Build)의 2단계 인덱싱 프로세스를 통해, 데이터 로딩, 청크(Chunk) 구성, LLM 기반 정보 추출, 그래프 및 벡터 인덱스 구축을 수행
지식 그래프(Knowledge Graph) 기반 RAG 시스템의 등장 배경
기존 RAG(Retrieval-Augmented Generation) 방식은 단순 키워드 매칭(Keyword Matching)에 의존하여, 질문과 직접적인 관련이 없는 정보는 검색하지 못하는 한계가 있었다. 본문에서는 이러한 문제를 해결하기 위해 지식 그래프(Knowledge Graph)를 활용하는 GraphRAG Toolkit을 소개한다.
벡터 유사성 검색(Vector Similarity Search)의 한계: 텍스트의 의미적 유사성만 고려하여, 데이터 간의 복잡한 관계를 파악하기 어려움
지식 그래프(Knowledge Graph)의 장점: 개체(Entity)와 관계(Relation)를 기반으로, 숨겨진 맥락과 연관 정보를 정확하게 찾아낼 수 있음