GPT-5.5, 솔직히 별로? 성능, 가격, 그리고 불편함까지!
by DD
2개월 전
조회수 2
OpenAI가 출시한 GPT-5.5 모델의 성능과 가격, 그리고 실제 사용 경험을 리뷰하며, 모델의 전반적인 특징을 소개함.
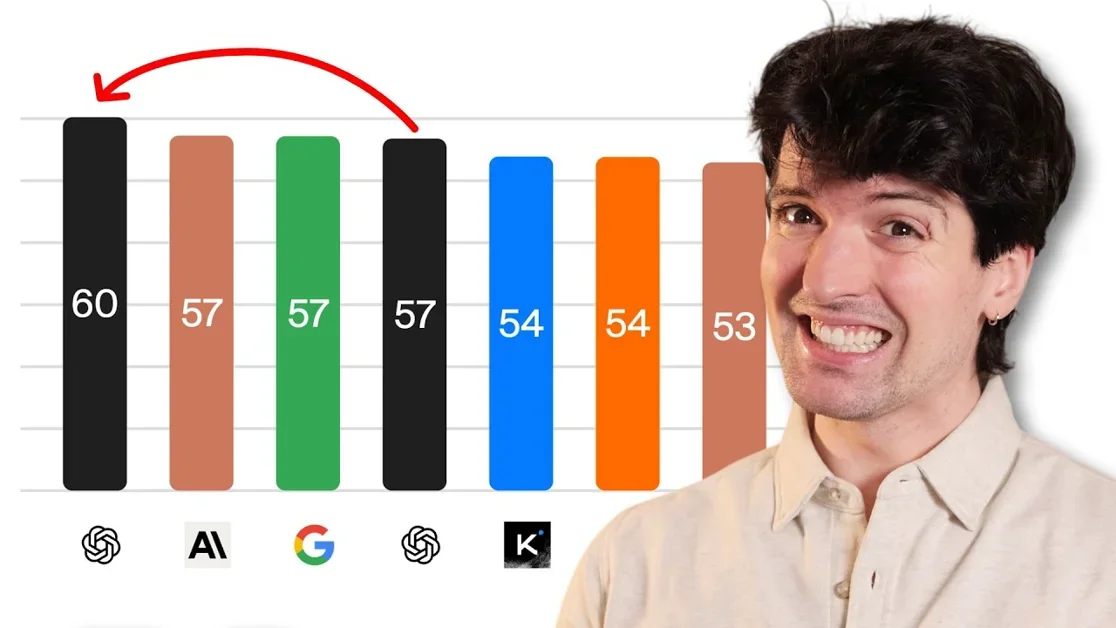
GPT-5.5의 벤치마크 결과를 분석하고, GPT-5.4 및 Anthropic Opus 4.7과의 성능 비교를 통해 모델의 강점과 약점을 파악함.
모델의 토큰 효율성 향상에도 불구하고, 가격 인상에 대한 아쉬움을 표현하며, 실제 사용 시의 불편함과 개선점을 지적함.
3D 게임 개발에 활용된 사례를 통해, 모델의 3D 이해 능력을 긍정적으로 평가하는 한편, 사용 편의성에 대한 개선을 요구함.
GPT-5.5의 가격 및 토큰 효율성 분석
발표자는 GPT-5.5의 가격이 입력 토큰당 5달러, 출력 토큰당 30달러로, GPT-5.4의 2배, Opus 4.7보다 약 20% 높다고 언급한다. 영상에서는 모델의 토큰 효율성(Token Efficiency)이 개선되었음에도 불구하고, 가격 인상에 대한 아쉬움을 표현한다. 발표자는 가격 인상에 대한 정당성을 찾기 어렵다고 말하며, 모델의 성능 향상과 비용 효율성 사이의 균형에 대한 의문을 제기한다.