넷플릭스, 모델 생명주기 그래프로 머신러닝(ML) 모델 관리 효율 극대화
by DD
2개월 전
조회수 34
넷플릭스는 머신러닝(Machine Learning) 모델의 다양한 도메인(Domain) 확장에 따라 모델 관리의 어려움을 겪음
모델 생명주기 그래프(Model Lifecycle Graph)를 구축하여 모델, 피처, 파이프라인 등 ML 관련 메타데이터(Metadata)를 통합 관리
메타데이터 서비스(Metadata Service, MDS)를 통해 실시간 메타데이터 수집, 관계 추론, 시각화 기능 제공
데이터 격리 아키텍처(Data Isolation Architecture)를 통해 각 도메인 간의 모델 및 데이터 공유를 지원하고, 재사용성(Reusability) 및 협업(Collaboration) 증진
향후 새로운 ML 도구 통합, 도메인별 시각화, 메타데이터 품질 향상, 고급 관계 추론 등 지속적인 시스템 개선 계획 발표
넷플릭스, 모델 생명주기 그래프(Model Lifecycle Graph)의 핵심 아키텍처
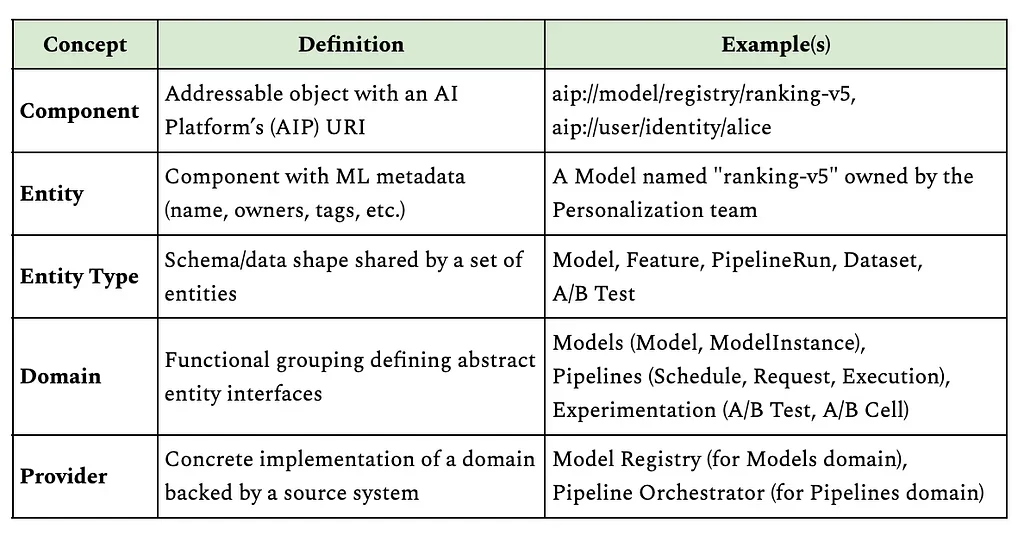
넷플릭스는 다양한 ML 도구(ML Tools) 및 도메인(Domain)에서 발생하는 메타데이터(Metadata)를 통합 관리하기 위해 메타데이터 서비스(Metadata Service, MDS)를 구축했다. MDS는 카프카(Kafka) 기반의 이벤트 스트림(Event Stream)을 통해 실시간으로 메타데이터를 수집하고, 데이터베이스(Database)로 Datomic을 사용해 관계를 저장한다. 또한, 엘라스틱서치(Elasticsearch)를 활용하여 빠른 검색 기능을 제공한다. MDS는 AIP URI(Uniform Resource Identifier) 기반의 컴포넌트(Component)를 사용하여 모델, 사용자, 파이프라인 등 ML 자산을 식별하고, 도메인(Domain) 및 프로바이더(Provider) 추상화를 통해 유연성을 확보했다. 이러한 아키텍처는 ML 자산의 발견 가능성(Discoverability), 이해 가능성(Understandability), 재사용성(Reusability)을 높이는 데 기여한다.
이벤트 기반(Event-Driven) 메타데이터(Metadata) 수집 및 처리
MDS는 이벤트 기반 아키텍처(Event-Driven Architecture)를 통해 다양한 소스 시스템(Source Systems)에서 발생하는 메타데이터를 수집한다. 카프카(Kafka) 및 AWS SNS/SQS를 통해 이벤트를 수신하고, 각 이벤트 타입에 맞는 핸들러(Handler)를 통해 처리한다. 이벤트가 도착하면 MDS는 소스 시스템 API를 호출하여 최신 상태를 가져오고, 이를 정규화된 엔티티(Entity)로 변환한다. 이 과정에서 데이터 정규화(Data Normalization)를 통해 각 시스템의 스키마(Schema) 차이를 해결하고, AIP URI를 활용하여 엔티티 간의 관계를 정의한다. 이러한 방식은 이벤트 순서에 독립적(Order-Independent)이며, 최신 상태(Latest State)를 보장하여 데이터 일관성을 유지한다. 또한, 지속적인 관계 추론(Relationship Inference)을 통해 모델과 A/B 테스트 간의 관계를 자동으로 연결한다.
Datomic과 엘라스틱서치(Elasticsearch)를 활용한 데이터 저장 및 검색
MDS는 Datomic을 사용하여 엔티티(Entity)와 관계를 저장하고, 엘라스틱서치(Elasticsearch)를 통해 빠른 검색 기능을 제공한다. Datomic은 불변성(Immutability)을 보장하는 팩트 모델(Fact Model)을 사용하여, 엔티티의 변경 이력을 추적하고 복잡한 그래프 탐색(Graph Traversal)을 지원한다. 또한, 관계(Relationship)를 효율적으로 저장하여 N+1 쿼리 문제를 방지한다. 엘라스틱서치(Elasticsearch)는 전체 텍스트 검색(Full-Text Search) 및 관련성 랭킹(Relevance Ranking)을 제공하며, 엔티티 이름, 설명, 태그(Tag) 등을 기반으로 검색을 수행한다. MDS는 Datomic과 엘라스틱서치(Elasticsearch)의 조합을 통해 빠른 검색(Fast Search)과 효율적인 관계 탐색(Efficient Relationship Exploration)을 동시에 제공한다.
모델 생명주기 그래프(Model Lifecycle Graph)를 통한 지식(Knowledge) 확장
MDS는 지속적인 지식 확장(Knowledge Enrichment)을 통해 모델 생명주기 그래프(Model Lifecycle Graph)를 구축하고, ML 자산 간의 관계를 자동으로 연결한다. 백그라운드 프로세스(Background Process)는 Datomic에 저장된 엔티티를 스캔하고, 미해결된 관계(Unresolved Relationships)를 식별한다. 이후, 소스 시스템(Source System) API를 호출하여 관련 엔티티 정보를 가져오고, 관계(Relationship)를 Datomic에 저장한다. 예를 들어, 모델 인스턴스(Model Instance)와 A/B 테스트 간의 관계를 연결하기 위해, 파이프라인(Pipeline) 정보를 활용하여 A/B 테스트 정보를 가져오고, 이를 모델 인스턴스와 연결한다. 이러한 과정을 통해 MDS는 수동적인 데이터 카탈로그(Data Catalog)에서 능동적인 추천 엔진(Recommendation Engine)으로 진화하며, ML 자산의 재사용성(Reusability) 및 협업(Collaboration)을 촉진한다.
향후 과제 및 개선 방향
넷플릭스는 모델 생명주기 그래프(Model Lifecycle Graph) 구축을 위한 지속적인 노력을 기울이고 있으며, 다음과 같은 과제를 해결해 나갈 예정이다.
새로운 ML 도구(ML Tools) 통합: 새로운 도구의 등장에 따라 플러그인 아키텍처(Plugin Architecture)를 설계하여 통합을 용이하게 할 계획이다.
도메인별 시각화(Domain-Specific Visualizations): 각 엔티티 타입에 맞는 맞춤형 시각화(Customized Visualization)를 제공하여 사용자 경험을 향상시킬 예정이다.
메타데이터 품질(Metadata Quality) 향상: 자동화된 검증 시스템(Automated Validation System)을 구축하여 메타데이터의 정확성(Accuracy)과 완전성(Completeness)을 높일 계획이다.
고급 관계 추론(Advanced Relationship Inference): 명시적인 관계 외에도, 암묵적인 관계(Implicit Connections)를 추론하여 ML 자산 추천 기능을 강화할 예정이다. 이러한 노력을 통해 MDS는 ML 엔지니어(ML Engineer)들이 신뢰하고 사용하는 핵심 도구로 자리매김할 것이다.