당근마켓, LLM으로 1만 개 카테고리 분류 시스템 구축
by DD
4개월 전
조회수 72
당근마켓은 중고거래, 모임 게시글 분류를 위해 LLM 기반 택소노미 관리 시스템(Taxonomy Management System)을 구축하고, 2조 토큰을 사용해 10,000개 이상의 카테고리를 분류함
Dataflow(Beam)을 활용하여 대용량 데이터 처리 파이프라인을 구축하고, BigQuery를 Source of Truth로 활용하여 분류 결과의 재사용성(Reusability)을 확보함
다양한 프롬프트 엔지니어링(Prompt Engineering), 모델 변경 실험, 임베딩 기반 분류 전략을 통해 비용 절감(Cost Reduction)과 정확도 향상을 동시에 달성함
LLM as a Judge 방식의 평가 체계를 도입하여 분류 품질(Classification Quality)을 지속적으로 모니터링하고 개선함
자체 모델 개발, 추론 품질 지표 고도화, 택소노미 체계 개선, Agent 활용 등 향후 택소노미 시스템 발전 방향을 제시함
Dataflow(Beam) 기반의 택소노미 파이프라인 아키텍처
당근마켓은 대용량 데이터 처리를 위해 Dataflow(Beam)를 선택하여 스트림 및 배치 처리를 통합했다. Dataflow는 자동 스케일링(Auto-scaling)을 지원하여 트래픽 변화에 유연하게 대응하며, Beam의 통합 프로그래밍 모델(Unified Programming Model)은 스트림과 배치 작업을 동일한 코드로 처리할 수 있게 한다.
BigQuery를 Source of Truth로 활용하여 분류 결과를 저장하고, 분석, 실험, 추천 모델 학습 등 다양한 용도로 재사용
YAML 기반의 설정 파일을 통해 택소노미 정의, LLM 모델, 파이프라인 설정을 관리하여 유지보수성(Maintainability)을 향상
Kafka를 통해 분류 결과를 피쳐 플랫폼에 적재하여 추천 엔진 및 검색 엔진에서 활용
LLM을 활용한 카테고리 분류 전략
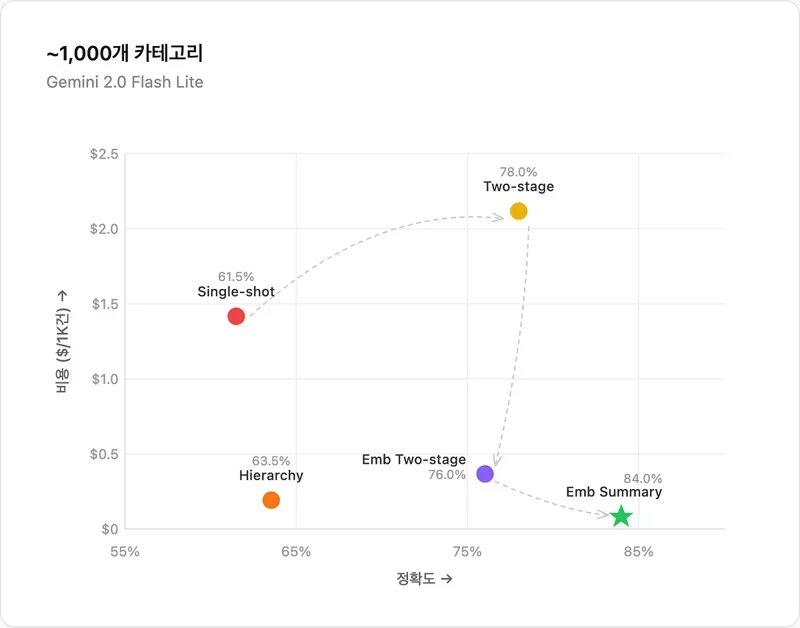
당근마켓은 LLM을 활용하여 10,000개 이상의 카테고리를 분류하기 위해 다양한 프롬프트 엔지니어링과 분류 전략을 시도했다. 초기에는 Single Shot, Hierarchical, Two-stage 방식을 사용했지만, 카테고리 수가 증가함에 따라 한계에 직면했다.
Embedding Two-stage 방식을 통해 게시글과 카테고리의 임베딩 유사도를 계산하여 후보군을 줄이고, 토너먼트 방식으로 최종 카테고리 선택
Embedding Summary 방식을 통해 게시글을 요약하고, 요약문을 기반으로 임베딩 유사도를 계산하여 분류 정확도 향상
BM25 키워드 매칭과 임베딩 유사도 검색을 결합한 하이브리드 방식을 통해 10,000개 규모의 택소노미에서도 높은 성능을 유지
LLM as a Judge 기반의 평가 체계
당근마켓은 LLM as a Judge 방식을 활용하여 분류 정확도를 평가하고, 모델, 프롬프트, 파이프라인 구조 변경에 따른 성능 변화를 측정했다. 여러 LLM 모델의 합의를 통해 Ground Truth를 생성하고, 이를 기반으로 Category Accuracy, Attribute Precision/Recall 등의 지표를 계산한다.
다양한 모델의 앙상블(Ensemble)을 통해 Ground Truth의 신뢰도를 높이고, 평가 체계의 객관성을 확보
지속적인 지표 트래킹(Metric Tracking)을 통해 데이터 트렌드 변화, LLM 서비스 상태 변화에 따른 성능 변동을 감지
Human-labeled goldset 샘플을 활용하여 평가 체계의 유효성을 검증하고, top-1 정확도뿐 아니라 depth별, 카테고리별 정확도 및 일관성 지표를 함께 분석
비용 효율적인 택소노미 운영을 위한 노력
당근마켓은 택소노미 시스템의 운영 비용을 절감하기 위해 다양한 시도를 했다. LLM API의 프롬프트 캐싱을 활용하고, 프롬프트 구조를 최적화하여 캐시 히트율을 높였다.
이미지 해상도 최적화를 통해 이미지당 토큰 사용량을 1/4로 줄이고, 이미지 개수를 줄여 전체 비용 절감
프롬프트 개선을 통해 정확도 향상과 비용 절감을 동시에 달성
모델 변경 실험을 통해 정확도와 비용 간의 Sweet Spot을 찾기 위한 노력을 지속
Embedding 기반 분류 전략을 통해 LLM 호출 횟수를 줄이고, 토큰 사용량을 절감하여 비용 효율성을 극대화
택소노미 시스템의 미래와 과제
당근마켓은 택소노미 시스템의 지속적인 발전을 위해 자체 모델 개발, 추론 품질 지표 고도화, 택소노미 체계 개선, Agent 활용 등 다양한 노력을 기울이고 있다.
자체 모델 개발을 통해 LLM API 호출 비용을 절감하고, 분류 품질을 유지
추론 품질 지표 고도화를 통해 카테고리별, depth별 정확도 및 오분류 샘플 분석을 통해 문제점을 파악하고 개선
택소노미 체계 개선을 통해 카테고리 및 속성 정의의 품질을 높이고, 체계 변경의 영향을 정량적으로 평가
Agent 활용을 통해 택소노미 정의, 번역, 전략 실험 등 운영 효율성을 극대화