Cloudflare, 보안 스캔 용량 10배 증설 성공!
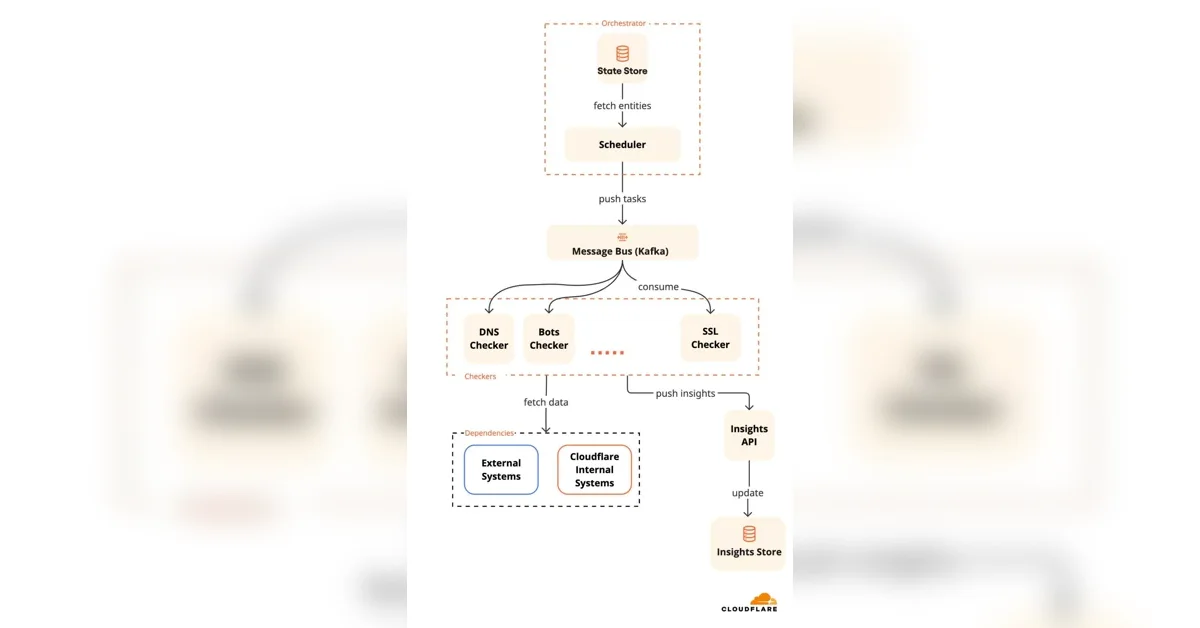
보안 인사이트(Security Insights)의 스캔 빈도 증가 및 모든 계정 자동 스캔 적용을 위해 처리량 10배 증설(10x Throughput Increase) 필요성 대두
기존 시스템의 잦은 API 타임아웃(API Timeout) 및 프로세스 크래시(Process Crash) 문제 해결을 위한 아키텍처 개선 진행
Apache Kafka 파티션(Kafka Partition) 및 Postgres DB 쿼리 최적화(DB Query Optimization), API 레이턴시(API Latency) 문제 해결을 통해 목표 초과 달성
Apache Kafka의 헤드 오브 라인 블로킹(Head-of-Line Blocking) 문제 해결
기존 Apache Kafka 시스템은 파티션 내 메시지 순서 보장으로 인해, 특정 느린 메시지(Slow Message) 처리가 전체 소비자 그룹의 진행을 막는 헤드 오브 라인 블로킹(Head-of-Line Blocking) 현상이 발생했다.
슬로우 레인(Slow Lane)과 패스트 레인(Fast Lane) 분리: 느린 메시지를 전담 처리하는 별도의 소비자 그룹을 도입하여 빠른 메시지의 진행을 보장함.
배치 처리(Batch Processing) 및 고루틴(Goroutine) 활용: 메시지 소비 시 여러 메시지를 한 번에 가져와 각 메시지를 별도의 고루틴에서 병렬 처리하여 처리량을 높임.
트레이드오프: 배치 처리 중 프로세스 크래시 시 재작업 필요성 증가 및 메모리 사용량 소폭 증가.
이러한 아키텍처 변경을 통해 메시지 처리 지연 시간(Message Processing Latency)을 크게 단축하고 전체 처리량을 증대시켰다.
Postgres 데이터베이스 쿼리 최적화 전략
기존 Postgres 데이터베이스에 인사이트 정보를 저장하는 과정에서, 수십만 건의 인사이트를 개별 INSERT 쿼리로 처리하여 DB 라운드 트립(DB Round Trip) 횟수가 과도하게 증가하는 문제가 있었다.
UNNEST 함수 활용: 소량의 인사이트 데이터는 `UNNEST` 함수를 사용하여 단일 쿼리로 효율적인 삽입을 수행함.
COPY 명령어 도입: 대량의 인사이트 데이터의 경우, 임시 테이블에 `COPY` 명령어를 사용하여 벌크 삽입(Bulk Insert) 성능을 극대화함.
하이브리드 접근 방식: 데이터 양에 따라 `UNNEST`와 `COPY`를 혼용하여 삽입 속도(Insert Speed)와 시스템 부하(System Load) 간의 균형을 맞춤.
이러한 최적화를 통해 대규모 데이터셋에서도 수 밀리초(Milliseconds)에서 수 초(Seconds) 내로 데이터 삽입을 완료할 수 있게 되었다.
API 레이턴시 문제 해결을 위한 아키텍처 변경
활성-활성(Active-Active)으로 운영되던 API 인스턴스가 지리적으로 분산되어 네트워크 레이턴시(Network Latency)로 인한 성능 저하가 발생했다.
지리적 분산 문제: 미국 오리건(Oregon)과 네덜란드 암스테르담(Amsterdam) 간의 왕복 지연 시간(Round-Trip Latency) 50ms가 API 응답 시간을 크게 증가시킴.
연결 풀 고갈(Connection Pool Exhaustion): 암스테르담 인스턴스의 느린 응답으로 인해 클라이언트 연결 풀이 고갈되어 타임아웃 발생 빈도 증가.
활성-수동(Active-Passive) 전환: API 인스턴스를 주 데이터베이스 위치인 오리건에 활성으로 두고 암스테르담을 수동으로 전환하여 데이터베이스 접근 지연 시간을 최소화함.
이 변경으로 API 응답 시간(API Response Time)이 평균 3초에서 수십 밀리초(Milliseconds)로 단축되었으며, 전반적인 시스템 안정성이 향상되었다.
스케줄러의 불균등한 스캔 트리거 문제 해결
기존 스케줄러 로직은 고정된 스캔 주기(Fixed Scan Interval)와 계정별 유사한 `last_scheduled_at` 값으로 인해 특정 시점에 수십만 건의 스캔이 몰리는 현상을 야기했다.
존(Zone)별 독립 스케줄링: 계정뿐만 아니라 각 존(Zone)별로 독립적인 스캔 주기를 관리하여 대규모 계정의 스캔이 다른 계정에 미치는 영향을 줄임.
`last_scheduled_at` 시간 무작위화(Randomization): 기존 데이터의 불균형을 해소하기 위해 스캔 시작 시간을 무작위로 조정함.
적응형 속도 제한(Adaptive Rate Limiting): 총 계정 수와 스캔 빈도에 따라 스캔 스케줄링 속도를 동적으로 조절하여, 신규 계정 추가 시에도 균일한 스캔 분산을 유지함.
이러한 변경으로 스캔 요청의 시간적 집중 현상(Temporal Concentration)을 완화하고 안정적인 스캔 처리가 가능해졌다.
10배 처리량 증설을 위한 엔지니어링 접근 방식
Cloudflare는 단순히 리소스(Pods, Partitions)를 추가하는 대신, 기존 시스템의 코드와 아키텍처를 깊이 이해하는 엔지니어링 접근 방식을 통해 처리량 10배 증설을 달성했다.
메트릭 기반 문제 해결: 로그와 메트릭을 면밀히 분석하여 API 타임아웃, Kafka 지연, DB 쿼리 비효율 등 근본 원인을 파악함.
쉬운 해결책 회피: API 클라이언트 측 타임아웃 증가와 같은 임시방편 대신, 근본적인 레이턴시 문제 해결에 집중함.
점진적 개선: 스케줄러 로직 수정, DB 쿼리 최적화, Kafka 처리 방식 개선 등 다각적인 엔지니어링 노력을 통해 시스템 안정성과 확장성을 동시에 확보함.
결론적으로, 문제의 본질을 파고드는 엔지니어링 문화가 120 scans/sec 이상의 피크 처리량을 달성하는 원동력이 되었다.