20년 치 채팅 분석, 관계의 비밀을 풀다!
by DD
1개월 전
조회수 10
저자는 20년간의 채팅 기록(Chat Logs)을 분석하여 관계의 변화를 추적하고, 데이터 기반의 관계 분석(Relationship Analysis)을 시도함
LLM(Large Language Model)을 활용하여 대화 내용 분류, 감정 분석, 인물 식별 등 복잡한 작업을 수행하고, 분석 결과 시각화
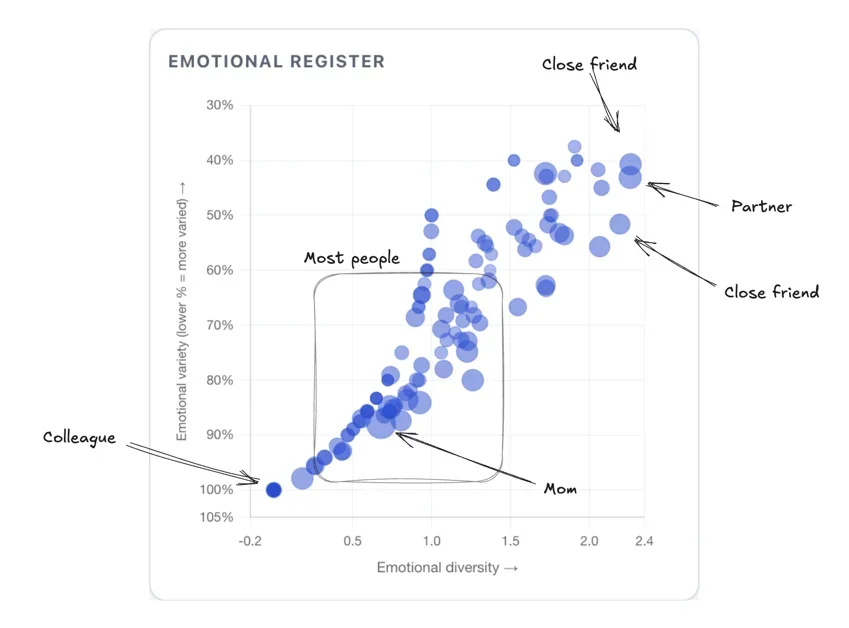
단어 사용 빈도, 질문 빈도, 대화량 변화 등을 통해 관계의 깊이와 변화를 객관적으로 측정하고, 관계 유지에 대한 통찰을 얻음
커뮤니티에서는 개인 정보 보호, 데이터 분석 방법론, LLM 활용에 대한 다양한 의견이 제시되었으며, 데이터의 안전한 관리(Secure Data Management)에 대한 우려도 제기됨
LLM을 활용한 데이터 분석 파이프라인
저자는 20년간의 채팅 데이터를 분석하기 위해 LLM(Large Language Model)을 활용하여, 대화 내용 분류, 감정 분석, 인물 식별 등의 작업을 수행했다. 특히, 데이터 미저장 정책(Zero-Retention Policy)을 통해 개인 정보 유출 위험을 최소화하고, 분석 결과만 저장하는 방식으로 시스템을 설계했다. 구체적으로, LLM은 6,000 메시지 이하의 청크(Chunk) 단위로 처리되며, 각 청크는 일별 노트, 인물 프로필, 타임라인 이벤트, 장소 업데이트, 그리고 해결되지 않은 모호성 목록을 포함하는 JSON 형식의 매니페스트를 생성한다. 이러한 매니페스트는 결정론적 스크립트에 의해 처리되어, 분석 결과가 SQLite 데이터베이스에 저장된다.
관계 변화를 보여주는 지표들
분석 결과, 저자는 단어 사용 빈도(Vocabulary Overlap), 질문 빈도(Question Rate), 그리고 대화량 변화(Message Volume)를 통해 관계의 변화를 파악했다. 특히, 친밀한 관계에서는 질문 빈도가 감소하고, 덜 친밀한 관계에서는 질문 빈도가 증가하는 경향을 발견했다. 또한, 대화의 감정적 온도 변화를 감지하기 위해, 대화 상대방과의 관계에서 나타나는 감정의 변화를 추적했다. 이러한 분석을 통해, 저자는 관계의 깊이와 변화를 객관적으로 측정하고, 관계 유지에 대한 통찰을 얻을 수 있었다.
데이터 분석 과정에서의 기술적 난관
저자는 데이터 분석 과정에서 다양한 기술적 난관에 직면했다. 특히, 여러 플랫폼에서 수집된 데이터를 통합하고, 인물 식별(Name Resolution)의 정확도를 높이는 데 어려움을 겪었다. 예를 들어, 동일 인물이 여러 플랫폼에서 다른 닉네임으로 사용되는 경우, LLM을 활용하여 이를 해결하고자 했다. 또한, 대화 내용에서 노이즈를 제거하기 위해, 짧은 단어, 이모지, 링크 등을 필터링하는 작업을 수행했다. 이러한 과정을 통해, 저자는 데이터의 품질을 높이고, 분석의 정확도를 향상시킬 수 있었다.
커뮤니티의 다양한 반응
커뮤니티에서는 개인 정보 보호, 데이터 분석 방법론, LLM 활용에 대한 다양한 의견이 제시되었다. 댓글에서는 데이터 분석의 윤리적 측면과 개인 정보 보호의 중요성을 강조하며, 데이터의 안전한 관리에 대한 우려를 표명했다. 또한 LLM의 성능과 한계에 대한 논의가 이루어졌으며, 데이터 분석 과정에서 발생할 수 있는 편향(Bias) 문제에 대한 지적도 있었다. 일부 사용자들은 자신의 채팅 기록을 분석하는 방법에 대한 질문을 던지기도 했다.