AI가 당신의 목소리로 노래한다!
by DD
7개월 전
조회수 10
AI Voice Conversion 기술은 LLM과 Generative Model 발전에 힘입어 발전함
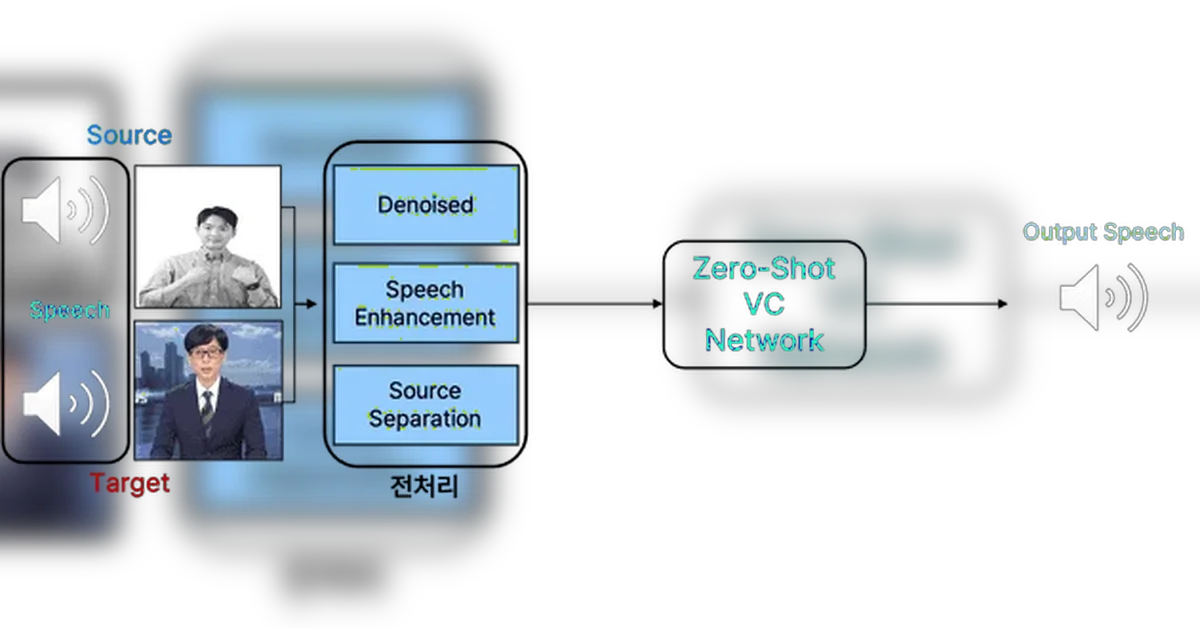
Speech/Singing Voice Conversion은 음성 특징 추출 및 변환을 통해 구현됨
U-DiT 기반 Diffusion Transformer Decoder와 BigVGAN Vocoder를 활용하여 고품질 음성 생성
음성 변환 파이프라인의 구조
Feature Extractor는 음성 신호에서 Spectrogram, Pitch, Semantic 특징을 추출한다. 구체적으로 Mel-Spectrogram을 통해 음성의 주파수적 특성을 파악한다. 따라서 Timbre Extractor는 음색 왜곡을 방지하고, Length Regulator는 시간적 일관성을 유지한다.
U-DiT 기반 음성 생성의 원리
U-DiT는 Diffusion Transformer Decoder를 활용하여 Style, Pitch, Semantic 정보를 결합한다. 구체적으로 Mel-Spectrogram을 생성하여 고품질 음성을 복원한다. 반면, Vocoder(BigVGAN)는 Mel-Spectrogram을 실제 오디오 waveform으로 변환하여 최종 음성을 완성한다.
음성 변환 기술의 도전 과제
음성 변환 기술은 생성 시간 및 GPU 자원 문제에 직면한다. 따라서 모델 경량화가 필수적이다. 학습 데이터 부족과 음색 왜곡 문제도 존재한다. 결과적으로 데이터 증강과 Speaker Embedding 정교화를 통해 품질을 개선해야 한다.