AI 에이전트 메모리, 리콜은 충분, 바인딩이 부족했다!
by DD
3개월 전
조회수 8
저자는 AI 에이전트 메모리 시스템인 OrKa Brain의 2차 실험에서 기존 시스템의 한계를 발견하고, 메모리 바인딩(Memory Binding)의 중요성을 깨달음
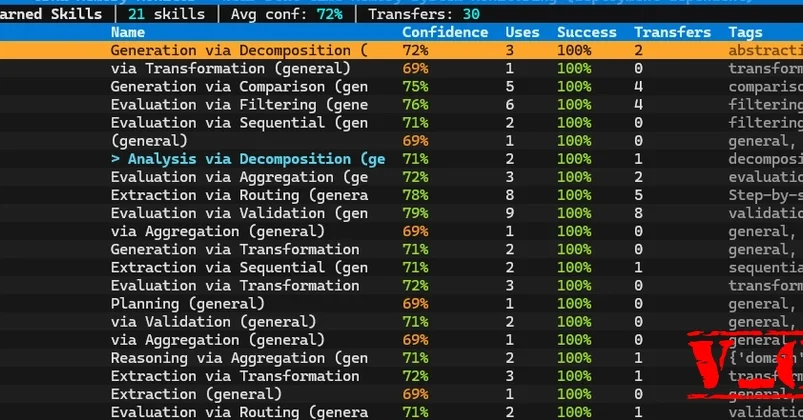
2차 실험에서 추상적인 기술(Abstract Skill)은 실제 작업에 활용되지 못하고, 의미 있는 성능 향상(Performance Improvement)을 이끌어내지 못함
저자는 기존의 Skill 시스템과 Episode 시스템을 연결하는 Memory Bundle 아키텍처를 제안하며, 실패 경험(Failure Experience)을 학습에 활용하는 방안 제시
Track C에서만 유의미한 성능 향상을 보인 이유는, 해당 트랙의 복잡한 라우팅 결정(Routing Decision)에 에피소드 기반 학습(Episode-based Learning)이 효과적이기 때문
OrKa Brain v1 vs v2: 실험 설계의 변화
저자는 기존 OrKa Brain v1의 문제점을 개선하기 위해, v2에서 다양한 변화를 시도했다.
추상화 계층(Abstraction Layer) 재설계: 기존의 구체적인 LLM(Large Language Model) 출력 대신, verb-target 패턴(Verb-Target Pattern)을 추출하여 일반화된 지식 저장
리콜 임계값(Recall Threshold) 조정: min_score=0.0에서 0.5로 상향, 의미론적 유사성(Semantic Similarity)과 구조적 일치(Structural Match)를 모두 고려하여 관련성 없는 지식(Irrelevant Knowledge) 필터링