Redis 기반 에이전트 기억(Agent Memory) 구현 시도: 절차적 기억 루프의 가능성을 엿보다
by DD
3개월 전
조회수 32
에이전트 시스템(Agent System)의 절차적 기억(Procedural Memory) 구현을 위해 Redis를 활용한 루프(Learn-Persist-Retrieve-Apply-Feedback-Decay)를 설계
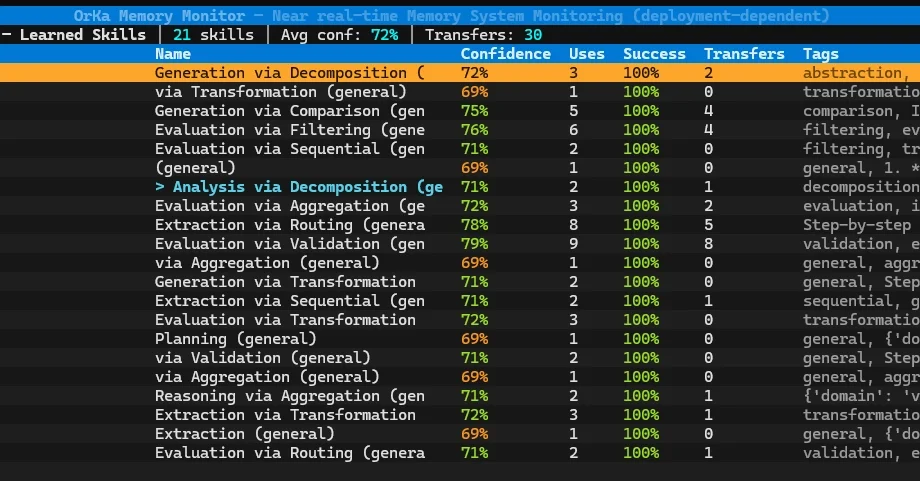
OrKa Brain을 통해 학습된 절차를 Redis에 저장하고, 다른 작업에 재사용하는 실험을 진행
30개의 작업(Task) 벤치마크 결과, Brain 조건이 63%의 head-to-head 승률을 기록하며 유의미한 성능 향상을 보임
평가 기준(Evaluation Criteria)의 한계로 인해, 절차적 기억의 실질적인 기여도에 대한 추가적인 분석 필요
향후 추상화(Abstraction) 및 검색(Retrieval) 개선을 통해 절차적 기억의 효과를 극대화할 계획
절차적 기억 루프(Procedural Memory Loop)의 기술적 구조
본문에서 제시된 절차적 기억 루프는 학습(Learn), 저장(Persist), 검색(Retrieve), 적용(Apply), 피드백(Feedback), 소멸(Decay)의 6단계로 구성된다. 학습 단계에서는 작업 수행 과정을 구조화된 스킬(Skill) 객체로 추출하며, 스킬은 순서화된 단계, 사전/사후 조건, 신뢰도 점수, 전이 기록, 사용 횟수, 태그, TTL(Time To Live) 등으로 구성된다. 저장 단계에서는 추출된 스킬을 Redis에 저장하고, 검색 단계에서는 구조적 유사성을 기반으로 관련 스킬을 탐색한다. 적용 단계에서는 검색된 스킬을 문제 해결 과정에 주입하고, 피드백 단계에서는 신뢰도를 업데이트하며, 소멸 단계에서는 오래된 패턴을 제거한다. 이러한 구조는 에이전트 시스템의 지속적인 학습과 적응(Continuous Learning and Adaptation)을 가능하게 한다.
Redis를 활용한 스킬 저장 및 관리
본 연구에서는 절차적 기억의 영속성을 위해 Redis를 활용하여 스킬을 저장한다. 스킬 객체는 순서화된 단계(Ordered Steps), 사전/사후 조건, 신뢰도 점수, 전이 기록, 사용 횟수, 태그, TTL(Time To Live) 등 다양한 정보를 포함하며, TTL은 사용 횟수와 신뢰도에 따라 동적으로 계산된다. Redis는 스킬의 저장, 검색, 관리에 사용되며, 특히 TTL 설정을 통해 사용되지 않는 스킬을 자동으로 삭제하는 메커니즘(Mechanism)을 제공한다. 이러한 Redis의 활용은 에이전트 시스템의 확장성(Scalability)과 성능(Performance)을 향상시키는 데 기여하며, 스킬의 효율적인 관리를 가능하게 한다.
벤치마크(Benchmark) 결과 분석: Brain vs Brainless
벤치마크는 30개의 작업(Task)을 대상으로, Brain 조건(6-agent pipeline)과 Brainless 조건(3-agent pipeline) 간의 성능을 비교했다. Brain 조건은 절차적 기억 루프를 활용하며, Brainless 조건은 절차적 기억 기능을 사용하지 않는다. 결과적으로 Brain 조건이 head-to-head 비교에서 63%의 승률을 기록하며, 유의미한 성능 향상(Significant Performance Improvement)을 보였다. 특히, 신뢰도(Trustworthiness) 측면에서 Brain 조건이 68%의 우위를 보였으며, 추론 품질(Reasoning Quality)에서 0.28점의 개선을 보였다. 하지만, 벤치마크 결과는 평가 기준(Evaluation Criteria)의 한계로 인해, 절차적 기억의 실질적인 기여도에 대한 추가적인 분석을 필요로 한다.
성능 개선을 위한 주요 과제: 추상화(Abstraction) 및 검색(Retrieval)
본 연구의 가장 큰 발견은 모델이 이미 절차적 패턴을 상당 부분 학습했다는 점이다. 따라서, 현재 시스템은 모델이 이미 알고 있는 패턴을 '상기시키는(Reminding)' 역할에 가깝다. 향후 성능 개선을 위해서는 추상화(Abstraction) 및 검색(Retrieval) 방식의 개선이 필요하다. 구체적으로, 현재의 키워드 기반 검색(Keyword-based Retrieval)을 임베딩 기반 검색(Embedding-based Retrieval)으로 대체하고, 절차를 도메인 독립적인 전술로 압축하는 것이 목표이다. 이러한 개선을 통해, 절차적 기억 루프가 모델의 기본 학습 능력 이상의 가치(Value)를 창출할 수 있을 것으로 기대된다.
벤치마크(Benchmark)의 한계와 개선 방향
벤치마크 결과는 긍정적이지만, 몇 가지 한계점(Limitations)을 가지고 있다. 첫째, 파이프라인 길이(Pipeline Length)로 인해, Brain 조건이 더 많은 LLM 호출을 거치면서 추가적인 컨텍스트를 얻었을 가능성이 있다. 둘째, 위치 편향(Position Bias)으로 인해, 첫 번째 조건이 더 높은 평가를 받을 가능성이 존재한다. 셋째, 단일 실행(Single Run) 기반의 결과이므로, 비결정성(Non-determinism)의 영향을 배제할 수 없다. 이러한 한계점을 보완하기 위해, 더욱 엄격한 평가 기준(Strict Evaluation Criteria)을 적용하고, 다양한 환경에서 벤치마크를 수행할 필요가 있다. 또한, 절차적 기억의 기여도를 정확하게 측정하기 위한 추가적인 연구가 필요하다.
향후 연구 방향: 절차적 기억의 실질적 가치 입증
저자는 향후 연구를 통해, 절차적 기억 루프가 모델의 성능을 실질적으로 향상시킬 수 있는지 검증하고자 한다. 이를 위해, 추상화(Abstraction) 및 검색(Retrieval) 기술을 개선하고, 다양한 도메인에서 벤치마크를 수행할 예정이다. 특히, 절차적 기억이 모델의 일반화 능력(Generalization Ability)을 향상시키고, 새로운 작업에 대한 적응력을 높이는 데 기여할 수 있는지에 주목할 필요가 있다. 궁극적으로, 절차적 기억 루프가 에이전트 시스템의 지능(Intelligence)을 향상시키는 데 기여할 수 있는지 확인하는 것이 목표이다.